Scaling Presto for Data Analytics - Insights from Meta, Uber, and Intuit
At PrestoCon Day 2023, we had a fantastic panel discussion with speakers from Meta, Uber, and Intuit. Each shared their experiences and use cases of scaling Presto in their respective companies. Let’s take a look at the key points discussed by each panelist, including use cases, key metrics, and future plans for Presto.
Presto at Intuit – leveraging Presto for analytics at scale
Shradha Ambekar, a software engineer at Intuit, started by providing insights into Intuit's use case for Presto. Intuit handles a massive amount of data, including hundreds of thousands of tables and petabytes of data. They serve over 100 million customers and have a comprehensive data architecture in place.

The data flows from various systems and formats into a clean data lake, where it is curated and persisted. Intuit primarily uses AWS S3 for data persistence and relies on Presto and Spark for data processing. They utilize Presto on Spark for exploration, operationalize queries through data pipelines, and leverage Tableau and Qlik Sense for data visualization.
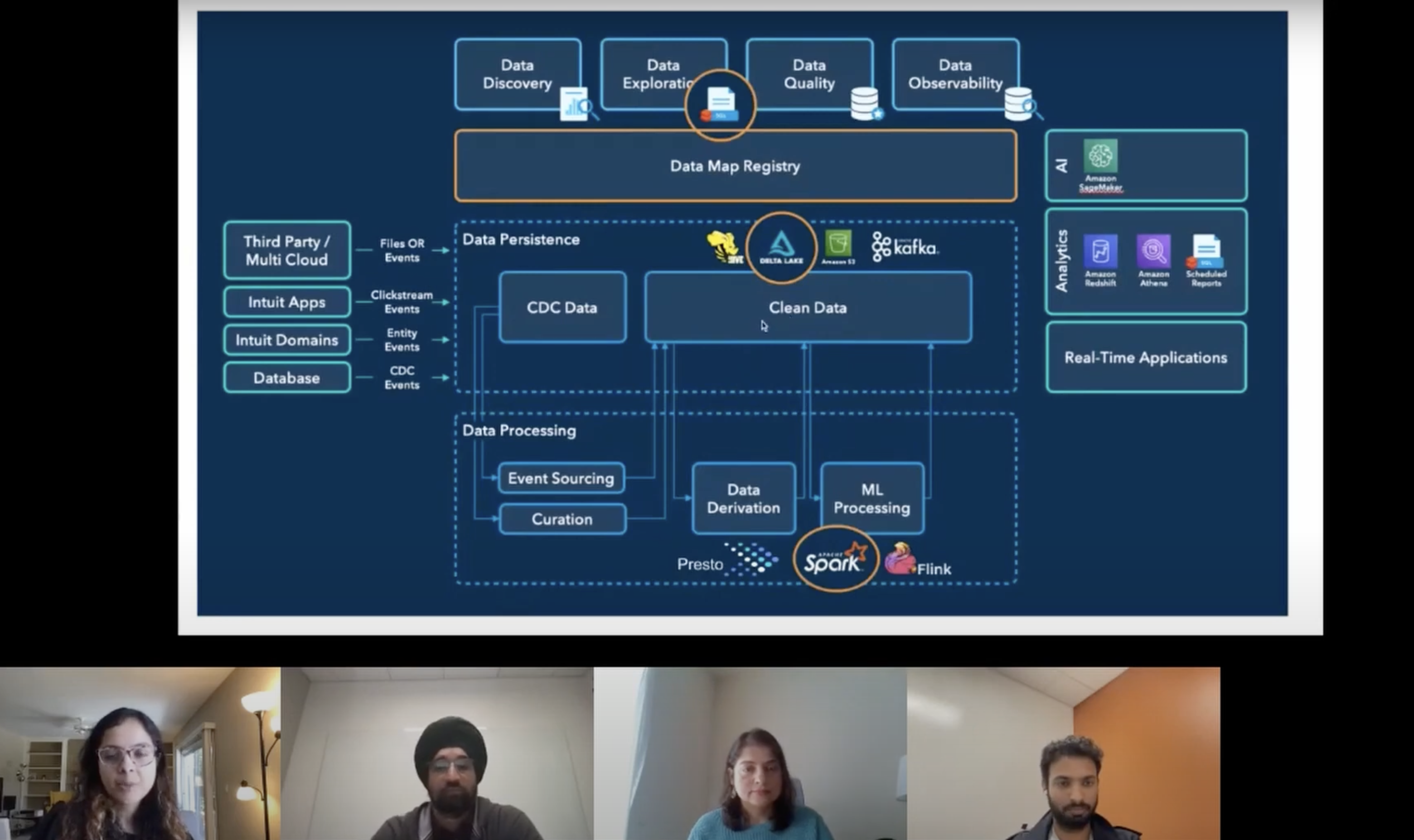
Key Metrics
Intuit has witnessed significant business impact and improved analyst productivity by adopting Presto on Spark. They handle thousands of jobs successfully running in production, resulting in thousands of estimated hours saved through the elimination of manual query conversion. Presto on Spark has helped to power Intuit's tax season which includes their analytics, marketing, and aggregate reports.
Future Plans
Intuit plans to further enhance their data architecture by evaluating Apache Iceberg for data processing. They aim to continue leveraging Presto on Spark for efficient data exploration and operationalization, thus enabling seamless query execution across different analytical workloads.
Presto at Meta - Scaling Presto for Interactive and ETL Workloads
Neerad Somanchi, a production engineer at Meta, shares insights into Meta's experience with Presto at scale. Meta initially adopted Presto to fulfill the need for fast interactive analytics. As its usage grew, Presto expanded its capabilities to handle lightweight ETL workloads. With different flavors of Presto, including Presto Unlimited and Presto on Spark, Meta serves a wide range of use cases. From exploratory SQL analytics to large batch ETL workloads, Presto offers an end-to-end solution that spans the entire data processing spectrum.
Key Metrics
Meta's data landscape involves hundreds of clusters and tens of millions of queries running daily. They process data at an exabyte scale, making Presto a critical component of their data warehouse infrastructure. The migration from Spark SQL to Presto has significantly improved query runtime and response time, benefiting tens of thousands of users within Meta.
Future Plans
Meta plans to consolidate their data warehouse workloads onto Presto as they migrate from Spark SQL to Presto. By standardizing on Presto, Meta aims to simplify their data processing architecture and further optimize the performance and scalability of their analytical workflows.
Presto at Uber - Enhancing User Experience with Presto
Gurmeet Singh, a software engineer in the Uber Presto team, discusses Uber's journey with Presto and its impact on user experience. Previously working in the storage domain, Gurmeet transitioned to the analytics layer at Uber, where he witnessed firsthand how Presto drives business use cases and improves user satisfaction. Key use cases are exploratory analytics for operations teams who want to do analysis on how operations are doing, as well as batch ETL workloads where you run a query on an ad hoc basis but you want to convert it to a pipeline. Dashboarding, reporting, and experimentation analysis are also done with Presto.
Key Metrics
Uber's focus is on delivering a seamless experience to users, whether it's timely Uber Eats deliveries or quick matching with rides. Presto plays a crucial role in ensuring efficient data processing and analytics to support these use cases. While he didn’t cover specific metrics, the emphasis is on delivering value to customers through Presto's capabilities.
Wrapping up – Presto at massive scale
This panel discussion highlighted the diverse use cases of scaling Presto for data analytics at Meta, Uber, and Intuit. Each company showcased their unique experiences and demonstrated how Presto has become a vital component of their data processing infrastructure.

Intuit, with its massive data landscape serving millions of customers, relies on Presto on Spark for data exploration and operationalization. By leveraging Presto, they have achieved significant business impact, improved analyst productivity, and streamlined their tax season analytics.
Meta processes data at an exabyte scale, benefiting tens of thousands of users and enhancing their data warehouse infrastructure with Presto.
Uber focuses on delivering a seamless user experience and utilizes Presto to support various business use cases, including efficient data processing for Uber Eats deliveries and quick matching with rides. Presto plays a critical role in business operations at Uber.
Overall, these three companies showcase the reliability of Presto as a powerful SQL query engine for scaling data analytics. Whether it's exploring vast amounts of data, performing ETL tasks, or optimizing user experiences, Presto proves its effectiveness in meeting the diverse needs of organizations across different industries. As Presto continues to evolve and improve, it is expected to play an even more significant role in the data analytics landscape in the future.
You can see the full panel presentation on the Presto Foundation YouTube channel.