Presto Unlimited: MPP SQL Engine at Scale

Wenlei Xie, Andrii Rosa, Shixuan Fan, Rebecca Schlussel, Tim Meehan
Presto is an open source distributed SQL query engine for running analytic queries against data sources of all sizes ranging from gigabytes to petabytes.
Presto was originally designed for interactive use cases, however, after seeing the merit in having a single interface for both batch and interactive, it is now also used heavily for processing batch workloads [6]. As a concrete example, more than 80% of new warehouse batch workloads at Facebook are developed on Presto. Its flexible “connector” design makes it possible to run queries against heterogeneous data sources — such as joining together Hive and MySQL tables without preloading the data.
However, memory-intensive (many TBs) and long-running (multiple hours) queries have been major pain points for Presto users. It is difficult to reason how much memory queries will use and when it will hit memory limit, and failures in long-running queries cause retries which create landing time variance. To improve user experience and scale MPP Database to large ETL workloads, we started this Presto Unlimited project.
Grouped Execution
Grouped execution was developed to scale Presto to run memory-intensive queries by leveraging table partitioning. See Stage and Source Scheduler and Grouped Execution for information about how it works.
Consider the following query, where table customer and orders are already bucketed on custkey:
SELECT ...
FROM customer JOIN orders
USING custkey
Without grouped execution, the workers will build hash table using all the data on the build side (Table orders):
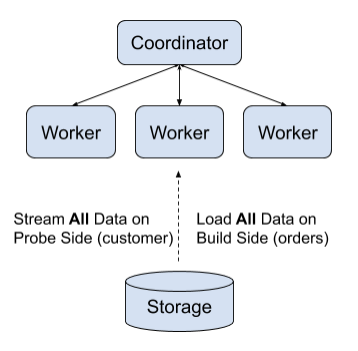
However, since customer and orders are already bucketed, Presto can schedule the query execution in a more intelligent way to reduce peak memory consumption: for each bucket i, joining the bucket i on table customer and orders can be done independently! In Presto engine, we call this computation unit a “lifespan”:
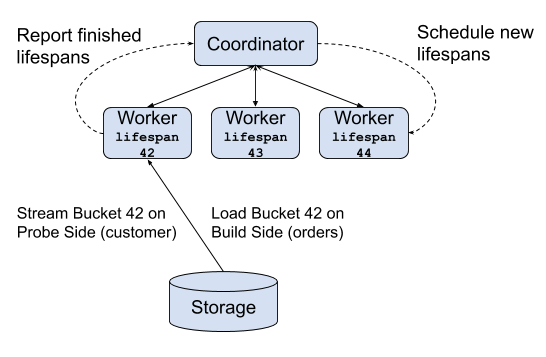
Grouped execution has been enabled in Facebook's production environment for over a year, and supports queries that would otherwise require tens of TBs, in some cases over 100 TB, of distributed memory.
Presto Unlimited
In this section we are going to introduce the two projects we worked on in the last half, aimed at the two pain points discussed in the introduction section:
- Exchange materialization for memory-intensive queries (many TBs)
- Recoverable grouped execution for long-running queries (multiple hours)
A few initial production pipelines in Facebook warehouse are already benefiting from these two features.
Exchange Materialization
While grouped execution serves as the foundation for scaling Presto to large batch queries, it doesn't work for non-bucketed tables. In order to make grouped execution work for such cases, we could materialize the exchange by writing data into intermediate bucketed tables.
Consider the same example query, the original simplified plan will be like the following:
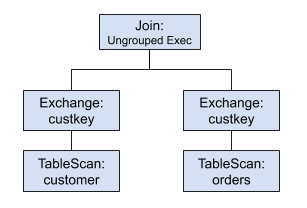
While the default remote network exchange is efficient and fast, it requires all the join workers to run concurrently. Materializing intermediate exchange data to disk opens opportunities for more flexible job scheduling, and using less memory by scheduling a group of lifespans at the same time.
When exchanges are materialized, the plan will first be “sectioned”, and ExchangeNode will be replaced by TableWriterNode/TableFinishNode and TableScanNode:
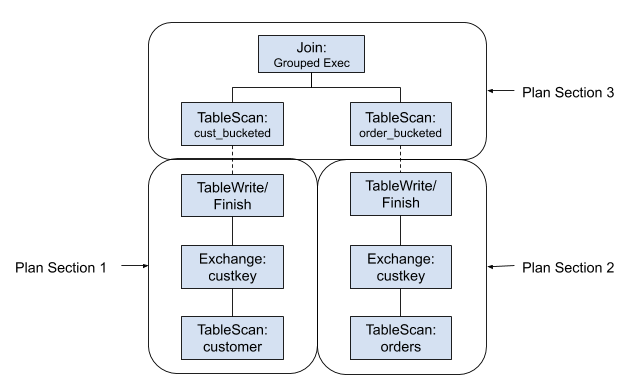
As a starting point, we introduced a new configuration to allow a query to materialize all exchanges (exchange_materialization_strategy). In the future, whether to materialize exchanges can be decided by Cost-Based Optimizer, or even user hints, in order to seek a better trade-off between reliability and efficiency.
For more details, please see the design doc at #12387.
Recoverable Grouped Execution
Grouped execution also enables partial query failure recovery, as now each lifespan of the query is independent and can be retried independently. As illustrated in the following figure:
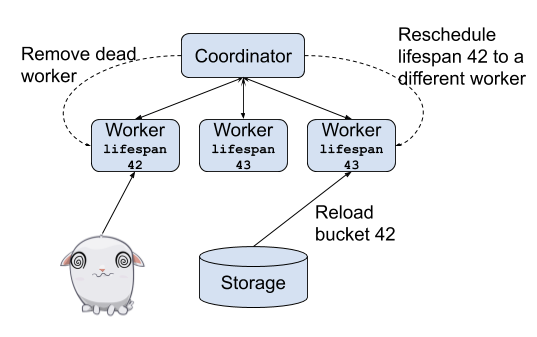
For more details, please see the design doc at #12124
Future Work
We are also thinking about the following future work:
Fault-Tolerant Exchange Execution
- With exchange materialization and recoverable grouped execution, the only reason that a single worker failure can fail the query is during the exchange stage.
- The long term, the solution is to implement MapReduce-style shuffle, or integrate with a fault-tolerant distributed shuffle service such as Cosco or Crail.
- The short term plan is to support recoverability for each execution section. Thus the query can restart from the last checkpoint instead of the beginning.
Reliable and Scalable Coordinator
- The coordinator becomes a single point of failure once query execution can survive worker failures.
- Coordinator high-availability and scalability is a crucial future work for Presto Unlimited project.
Resource Management for Presto Unlimited
- With more larger queries onboard we need to actively monitor whether the current resource management needs improvement and adapt to the potential workload shifts introduced by Presto Unlimited.
- Lifespan provides a unit for resource management at fine granularity in addition to being a smaller unit of retry. This opens opportunities for fine-grained resource management.
Parallel Databases Meet MapReduce
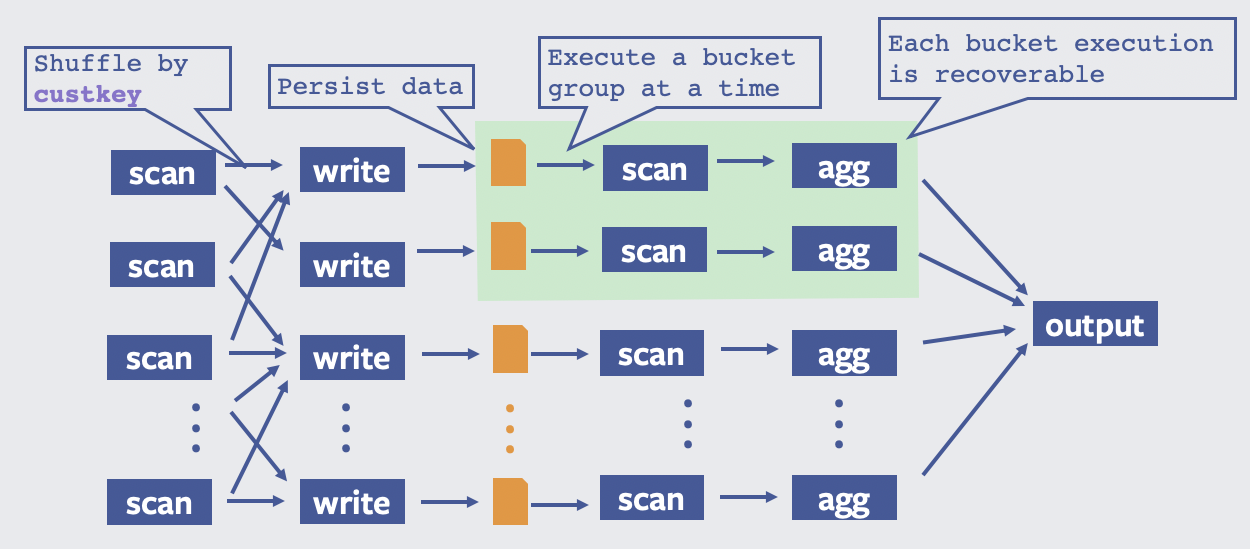
With Presto Unlimited, Presto executes large ETL queries in a similar way to MapReduce. Consider the following simple aggregation query:
SELECT custkey, SUM(totalprice)
FROM orders
GROUP BY custkey
The following figure illustrates how the query will be executed with Presto Unlimited:
In comparison, here is how the query will be executed without Presto Unlimited:
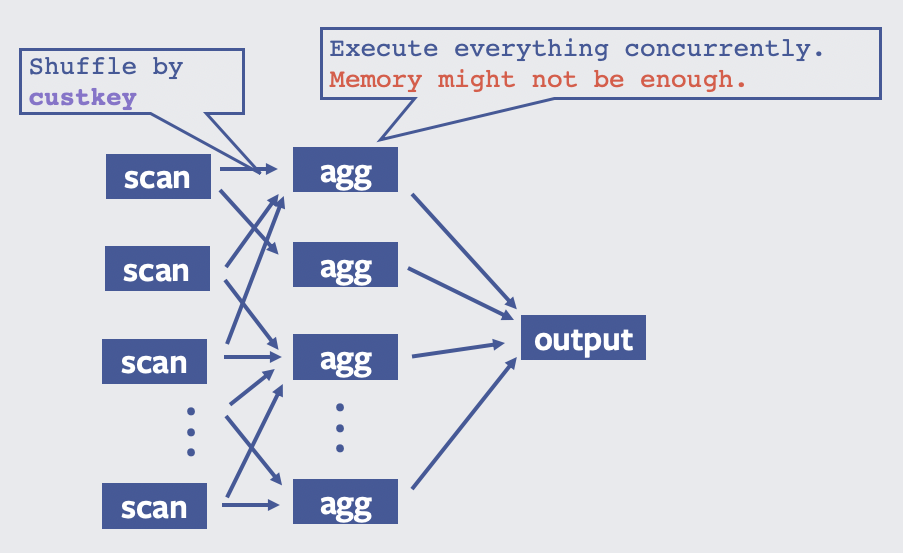
Spilling is used in parallel databases to support memory-intensive queries [5, 7]. Note spilling and Presto Unlimited leverage the same fundamental idea: first partition data into intermediate result, and operate on a small chunk of data at a time to reduce peak memory usage. Spilling does this in a lazy fashion: it only writes intermediate data when the join/aggregate is running out of memory, while Presto Unlimited eagerly materializing intermediate results prior to the join/aggregation execution. This MapReduce-style execution also allows much easier fault-tolerance implementation, as each partition can be retried independently.
During the last decade, the standard approach to support SQL at scale is to build parallel database on a MapReduce-like runtime: Tenzing [1], Hive [2], SCOPE [3], SparkSQL [4], F1 Query [5], etc.
To the best of our knowledge, Presto Unlimited is the first attempt to meet parallel database and MapReduce in a different direction, as it brings MapReduce-style execution to the parallel database.
Reference
[1] Tenzing A SQL Implementation On The MapReduce Framework
[2] Hive - A Petabyte Scale Data Warehouse using Hadoop
[3] SCOPE: parallel databases meet MapReduce
[4] Spark SQL: Relational Data Processing in Spark
[5] F1 Query: Declarative Querying at Scale
[7] HAWQ: A Massively Parallel Processing SQL Engine in Hadoop