Improving the Presto planner for better push down and data federation
Alibaba: Yuan Mei
Facebook: James Sun, Maria Basmanova, Rongrong Zhong, Jiexi Lin, Saksham Sachdev
Pinterest: Yi He
University of Waterloo: Akshay Pall
Presto defines a connector API that allows Presto to query any data source that has a connector implementation. The existing connector API provides basic predicate pushdown functionality allowing connectors to perform filtering at the underlying data source.
However, there are certain limitations with the existing predicate pushdown functionality that limits what connectors can do. The expressiveness of what can be pushed down is limited and the connectors can't change the structure of the plan at all.
This image shows what the planner and connector interaction used to look like:
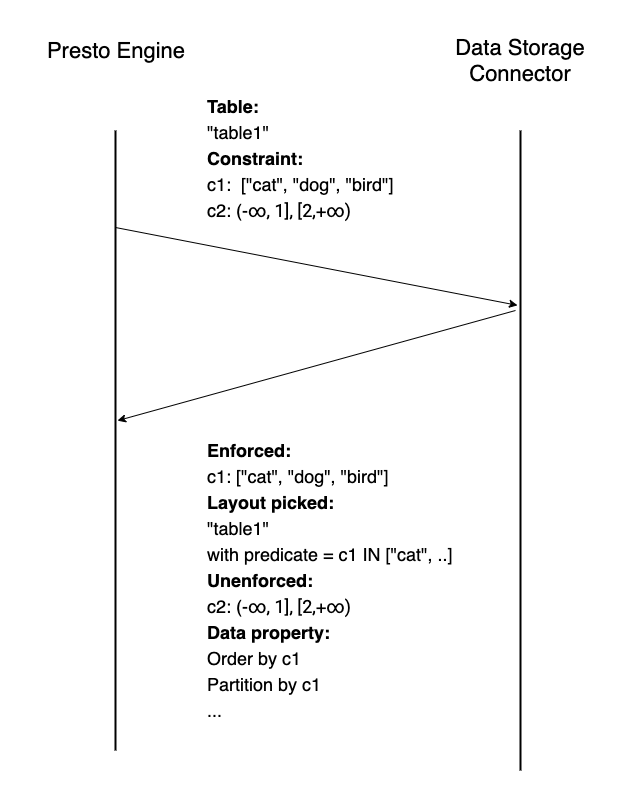
First, Presto only supports predicate push down through connector provided methods. If Presto needs to push down a set of operations (for example, projection/filter/aggregation/limit), then the connectors need to support several methods:
pushDownFilterLimitScan
pushDownProjectFilterScan
...
This increases the complexity of creating and maintaining a connectors. Also, as we will show later, we not only want to push down operations, but also add new operations into a query plan. The current planner model does support many useful connector driven plan changes.
Second, the range of predicates and operators that can be pushed down is limited. Only predicates that can be represented by a data structure called TupleDomain, can be pushed down. This data structure only supports ANDed predicates that determine whether a variable/column is in a value set (ranged or equitable). There is thus no way to describe complex predicates like 'A[1] IN (1, 2, 3)' or ‘A like 'A Varchar %'’.
A more flexible approach would be to push down the entire expression which is currently represented as an Abstract Syntax Tree (AST). One problem with this approach is that the AST evolves over time such as when new language features are added. Additionally the AST does not contain type information as well as enough information to perform function resolution.
Functions can now resolve to different implementations thanks to the recently added dynamic function registration. Dynamic function registration allows users to write their own SQL functions. For example, a user can update the definition of a SQL function in another session while queries using the function are still running. If we were to perform function resolution at invocation time then we could end up using different implementations within the same session and query. If we are going to support materialized views, we also need to make sure the function version is consistent between the data reader and writer.
We resolve this by storing function resolution information in the expression representation itself as a serializable functionHandle. This makes it possible to consistently reference a function when we reuse the expressions containing the function.
Types present a similar issue. Connectors can’t safely rely on metadata to know the type of a variable. The metadata describing the variable might be unavailable or have changed during execution.
We have gradually improved the Presto planner’s ability to push down more expressive operations between version 0.217 and 0.229. We also made corresponding updates to connectors allowing them to understand and operate on plan sub-trees.
Exposing plan sub-trees to connector
Presto executes a SQL query by first parsing it to an Abstract Syntax Tree (AST). The AST is then converted to logical plan tree, which represents the relational algebra contained in the query. The relational algebra representation is not optimized and lacks sufficient physical layout information for query execution.
Presto uses a list of optimizers to transform the logical plan to an optimized physical plan. Each plan optimizer can operate on sub-trees of the whole plan tree and replace them with more optimized sub-trees based on heuristic or statistics. Optimizers can save the physical information of execution on a set of connector provided handles (for example, ConnectorTableHandle, ConnectorTableLayoutHandle, ConnectorPartitionHandle, …).
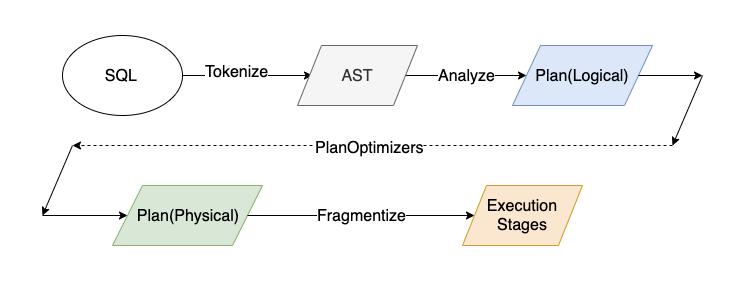
Unlike some other SQL engines, Presto does not explicitly set the boundary between the logical plan and physical plan. Instead, there are a few crucial optimizers that transform the logical plan into a physical one.
PickTableLayout and AddExchanges are two of the more important optimizers.
PickTableLayout plans predicate push down into a table scan by calling the connector provided API method getTableLayout. It is also used to obtain physical layout information from the connector. getTableLayout returns a LayoutHandle that the connector populates with information on the structure of the data that will be returned by the scan. Presto will later use the LayoutHandle to plan, optimize, and execute the query.
AddExchanges adds the data shuffling (data exchange) operators to a query execution. This important step determines how query execution is parallelized, and how data is redistributed for processing at each stage of a query. A stage of execution in Presto is generally the shuffling of data on the partition key that is required for processing the next part of a query plan. AddExchanges relies on the Handle returned from the connector to decide on the appropriate places and kinds of exchanges to add to the plan.
Relying on PickTableLayout to do both predicate push down and physical planning is very restrictive because there is no way for connectors to modify the plan beyond basic predicate pushdown.
Presto now allows connectors to provide optimization rules to the Presto engine, which allows connectors to introduce arbitrary optimizations. There are restrictions to prevent connector provided optimizers from accidentally changing another connector’s sub plan:
- PlanNodes that are exposed to presto-spi module.
- PlanNodes that belong to the connector.
A sub max tree that satisfies the above rules will be transformed to more optimized form picked by a connector provided optimization rule:
public interface ConnectorPlanOptimizer
{
PlanNode optimize(
PlanNode maxSubplan,
ConnectorSession session,
VariableAllocator variableAllocator,
PlanNodeIdAllocator idAllocator);
}
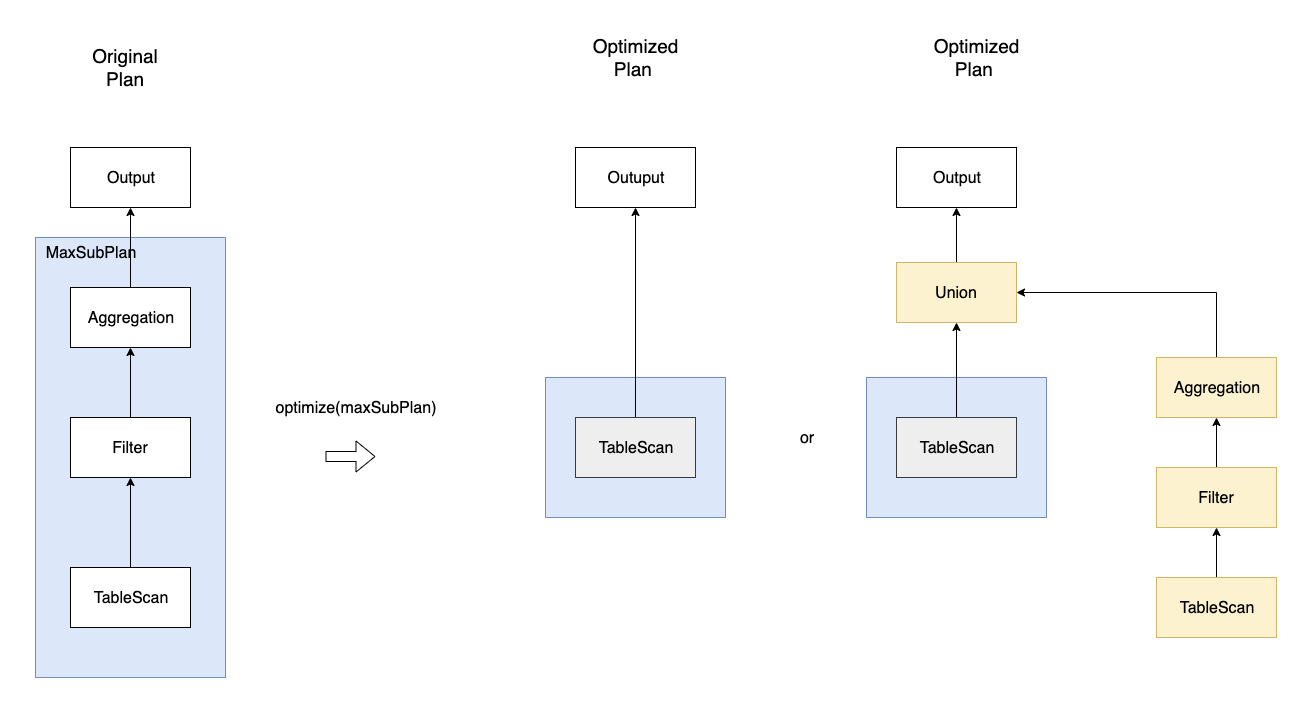
Note that, the above rule only applies to the maxSubPlan optimizer taken as input. It is quite possible a connector provided optimizer can generate a new plan contains nodes belonging to another connector (usually during a view expansion). In such cases, TableScan might be reading from a virtual table combining data from multiple different data sources. The TableScan on the virtual table can be expanded to a new sub tree that unions TableScans from both sides. Once expanded, the optimization of newly generated plan nodes can then be handled by the connectors they belong to, so that most optimized subplan can be achieved.
The connector rule will transform the sub max plan tree. In the case of predicate pushdown (taking MySQLConnector as an example), the connector can save the predicates that MySQL can handle as a SQL expression inside MySQLConnectorLayoutHandle and return a TableScan node.
The engine will apply the connector optimization rules at critical plan transformation checkpoints:
All rules that are operating on logical plans will be applied once before AddExchange to start the transformation into physical plan. At this point, we can expand views and push down many operations.
Some optimizations that rely on physical information need to be applied later at the end of optimization cycle. For example, we may want to only push down part of an aggregation into the connector in order to still benefit from parallel execution. Splitting up the aggregation stages happens after the exchange nodes are added.
More descriptive expression language
We also replaced AST-based expression representation with a new representation called RowExpression. RowExpression is completely self-contained and can be shared across multiple systems. The new representation has several sub-types:
| ExpressionType | Represents |
|---|---|
ConstantExpression | Literal values such as (1L, BIGINT), ("string", VARCHAR) ... |
VariableReferenceExpression | Reference to an input column and a field of the output from previous relation expression. |
CallExpression | Function calls, which includes all arithmetic operations, casts, UDFs, … with function handle resolved. |
SpecialFormExpression | Special built-in function calls that is generic to any types or can only have single type(Boolean) thus function handle is not necessary. Examples are: IN IF, IS_NULL, AND,OR, COALESCE, DEREFERENCE, ROW_CONSTRUCTOR, BIND, ... |
LambdaDefinitionExpression | Definition of anonymous (lambda) functions. For example: (x:BIGINT,y:BIGINT):BIGINT -> x+y |
How are we using it so far:
Aria Scan filter pushdown
Project Aria Scan aims to improve the CPU efficiency of table scan by pushing filters into the scan. The new planner provides native support for the filter pushdown required here.
Uber Pinot connector
Uber uses AresDB and Pinot to serve their real time analytics([1][2][3]). These systems are very fast, but have limited SQL support. Presto can provide full SQL support on top of these systems to satisfy the growing need for complex analytics.
AresDB and Pinot can handle certain subsets of localized relational algebra. Being able to push down those operations means better efficiency and lower latency. Recently, Uber has contributed the Pinot connector to PrestoDB which leverages the new connector architecture to push down aggregations and filters into Pinot.
Uber is actively working on a Presto-AresDB connector to do the same.
Scuba
At Facebook, we use Scuba for analytics on real time data. The new connector architecture allows pushing down filters and aggregations into these systems to achieve better efficiency and latency.
Scuba is a Facebook internal system offering real time ingestion with limited retention. There are many use cases where recent data, from the last hour or day, is stored in Scuba and older data is stored in Hive. We built a Scuba connector for Presto to allow users to query data from both Hive and Scuba in the same query.
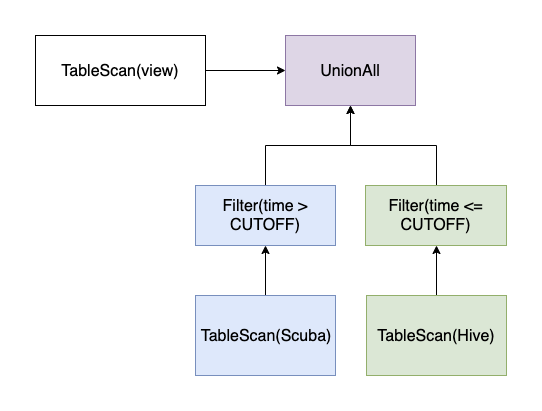
We also built views that combine Scuba tables with their Hive counterparts to allow for seamless querying. The support for views spanning two connectors was made possible by the new planner architecture. The connector expands the table scan node referring to the view into a union of table scans: one from Scuba, and one from Hive.
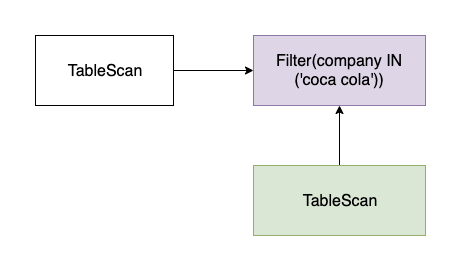
Row level security
Sometimes we want to add filters dynamically, e.g. based on who is querying the data. For example, an employee of Coca Cola shouldn’t see records from Pepsi. We built an optimizer rule that conditionally adds Filter node on top of the TableScan node based on the query user and table structure.
What’s next?
Even though the planner changes are already delivery benefits, we are still only half way there:
Not all optimization rules are using RowExpression at the moment. We are actively migrating all optimization rules to use RowExpression. In today’s version of Presto, we still rely on both connector provided optimization rules and the old API to plan for different data sources. Over time we will unify them.
We also want to add support for traits to simplify the mechanism for obtaining data layout information. In the long run, we are hoping our planner can be exploratory which means we can find the lowest cost (most optimized) plan through many different optimization combinations.
[1]https://www.slideshare.net/XIANGFU3/pinot-near-realtime-analytics-uber