Querying Nested Data with Lambda Functions

Denormalized data with nested values (e.g. array/map) have become omnipresent in this Big Data era, as a lot of data naturally conforms to a nested representation [1, 2]. As a result it is important to provide an efficient and convenient way to query nested data. SQL traditionally does not include support for this.
The pioneering work of Dremel proposed an extension to SQL based on recursive relational algebra to allow querying nested records [1], and is now available in BigQuery and the SQL:2016 standard. The following example shows how to transform array elements with this (adapted from BigQuery Docs):
SELECT elements,
ARRAY(SELECT v * 2
FROM UNNEST(elements) AS v) AS multiplied_elements
FROM (
VALUES
(ARRAY[1, 2]),
(ARRAY[1, 3, 9]),
(ARRAY[1, 4, 16, 64])
) AS t(elements)
elements | multiplied_elements
----------------+---------------------
[1, 2] | [2, 4]
[1, 3, 9] | [2, 6, 18]
[1, 4, 16, 64] | [2, 8, 32, 128]
(3 rows)
While nested relational algebra provides an elegant and unified approach to query nested data, we found it could be challenging for users to track the “unnest stack” in mind when writing the query. In our experience, users are more comfortable to apply a given function (e.g lambda) to each element in the collection. This motivates us to introduce lambda expressions into Presto to help query nested data, as illustrated below:
SELECT elements,
transform(elements, v -> v * 2) as multiplied_elements
FROM (
VALUES
(ARRAY[1, 2]),
(ARRAY[1, 3, 9]),
(ARRAY[1, 4, 16, 64])
) AS t(elements)
In Presto, a lambda expression consists of an argument list and lambda body, separated by ->:
x -> x + 1
(x, y) -> x + y
x -> regexp_like(x, 'a+')
x -> x[1] / x[2]
x -> IF(x > 0, x, -x)
x -> COALESCE(x, 0)
x -> CAST(x AS JSON)
x -> x + TRY(1 / 0)
Note there is no type annotation in a lambda expression. The type of a lambda expression (e.g. function(integer, integer)) thus has to be inferred from the context of function call. As a result, standalone lambda expressions are not allowed since their types cannot be determined.
Lambda Type Inference
The initial lambda support in Presto was added in Presto#6198 with basic compilation and execution. One of the major challenges this pull request addressed was type inference for lambda, as there is no type annotation in lambda expressions. Consider the following expression contains lambda:
transform(elements, v -> v * 2)
where elements is with type array(integer).
Presto allows function overloading, and the exact function match is resolved by looking up the function name and argument types. This is infeasible for higher-order functions as the type for v -> v * 2 cannot be resolved without context.
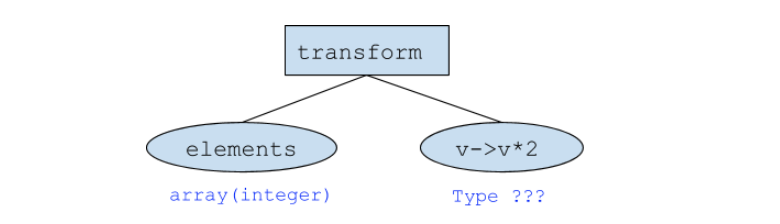
As a result, Presto doesn’t allow function overloading for higher-order functions, thus it can still resolve the function transform just by the name. ExpresionAnalyzer will have the following information:
- The generic type for
transformis(array(T), function(T, U)) -> array(U). - The first argument type is
array(integer). - The exact type for the second argument
v -> v * 2is unknown since it’s a lambda expression. However, its type can be uniquely determined once the input parameter type is bound. This is done by the TypeSignatureProvider class.
The type parameter T and U needs to be determined to resolve the expression type. This is done by SignaturerBinder#bind method. SignaturerBinder#appendConstraintSolvers is called under the hood to iteratively solve this constraint satisfaction problem. A new TypeConstraintSolver called FunctionSolver was added for updating type constraints related to lambda expressions.
Lambda Capture
Lambda capture allows users to refer to other columns in the lambda function, for example:
SELECT elements,
transform(elements, v -> v * factor) as multiplied_elements
FROM (
VALUES
(ARRAY[1, 2], 2),
(ARRAY[1, 3, 9], 3),
(ARRAY[1, 4, 16, 64], 4)
) AS t(elements, factor)
elements | multiplied_elements
----------------+---------------------
[1, 2] | [2, 4]
[1, 3, 9] | [3, 9, 27]
[1, 4, 16, 64] | [4, 16, 64, 256]
(3 rows)
Lambda capture supported is added in Presto#7210. It rewrites the captured lambda into non-capture lambda via partial function application. A special internal higher order function BIND is introduced to partially apply captured arguments to the lambda.
Take the above example, the captured lambda call
transform(elements, v -> v * factor)
is rewritten to
transform(
elements,
BIND(factor, (captured_factor, e) -> e * captured_factor)
)
The original unary lambda with capture e -> e * factor is rewritten into a binary lambda without capture: (captured_factor, e) -> e * captured_factor. The BIND call takes factor and this binary lambda as input, returns the partially applied function that multiplies the input by captured_factor (Note the captured_factor will be different for each row!). This partially applied function is a unary function and is provided as the second parameter to transform call.
Lambda Execution
In this section we are going to discuss how a lambda is executed during runtime. The original implementation used MethodHandle objects to represent lambdas on the stack. Consider the same example:
transform(
elements,
BIND(factor, (captured_factor, v) -> v * captured_factor)
)
Each invocation of transform works in the following way:
- Push the Java object representing elements on the stack. When
elementsisarray(integer), the corresponding Java stack type isIntArrayBlock. - Push the
MethodHandleobject representing captured lambda to the stack, i.e. bindingfactorto(captured_factor, v) -> v * captured_factor. To this end:- Push the
MethodHandleobject representsv -> v * captured_factoronto the stack. - Push
captured_factoron the stack. - Invoke
MethodHandle#bindToto get aBoundMethodHandlerepresenting captured lambda on the top of stack.
- Push the
- Invoke
transform.
Unfortunately, this implementation causes Java to generate a separate customized LambdaForm class for every MethodHandle#bindTo call (i.e. per each row). Such excessive runtime class generation quickly fills the Metaspace and causes full GC, see Presto#7935 for reproduction and details. JDK developers have confirmed that each BoundMethodHandle should be customized independently, and MethodHandle#bindTo is not a good fit for implementing lambda capturing.
To fix this, we redesigned Presto lambda execution via Presto #8031. The key observations are:
- Lambda capture has to be performed per invocation, as different value will be captured for each row.
- However, we should use the same class representing captured lambda for every
BINDcall, otherwise we will generate too many classes.
We use the same approach as Java uses to handle lambda and capture [3, 4]:
- A lambda is represented as an object whose type is a functional interface (a.k.a. Single Abstract Method class)
- The
invokedynamicinstruction is used to perform lambda capture:- During the first
invokedynamiccall, the class representing the captured lambda (which is a functional interface) is created and a method to perform the capture is generated in it. This step is also called linkage and will only be done once. - Every
invokedynamiccall performs capture and returns an instance of the desired functional interface.
- During the first
With this design, BIND function will always be fused together with the lambda generation step to generate a captured lambda in a single step -- we cannot first generate an object representing the uncaptured lambda, and then perform a separate partial application step. Note this implementation also doesn't allow more general higher-order functions that return a function as result.
Lambda in Aggregation
While lambda was originally introduced to help query nested data with scalar functions, we also noted it can be used in aggregation functions to allow more flexible analytics. The initial support for lambda in aggregation was added in Presto#12084, with a reduce_agg function for demonstration purposes. reduce_agg conceputally allows the creation of User-Defined Aggregation Function (UDAF) by making the input and combine functions lambdas. The following example shows how to use reduce_agg to compute group-wise product (instead of sum):
SELECT id,
reduce_agg(value, 1, (a, b) -> a * b, (a, b) -> a * b) prod
FROM (
VALUES
(1, 2),
(1, 3),
(1, 4),
(2, 20),
(2, 30),
(2, 40)
) AS t(id, value)
GROUP BY id;
id | prod
----+-------
2 | 24000
1 | 24
(2 rows)
Unfortunately, due to JDK-8017163, aggregation state with Slice or Block as a native container type is intentionally not supported yet. It can result in excessive JVM remembered set memory usage. This is because aggregation state requires updates in unpredictable order, resulting in a huge amount of cross-region references when each state is a separate object. This issue is also reported in Presto#9553. This makes this function not yet practically useful. Once JDK-8017163 is fixed in later versions of the JVM, we are looking forward to enabling it with more general types to allow more flexible analytics in aggregations!
Reference
[1] Dremel: Interactive Analysis of Web-Scale Datasets
[2] Everything You Always Wanted To Do in Table Scan