Engineering SQL Support on Apache Pinot at Uber
The article, Engineering SQL Support on Apache Pinot at Uber, was originally published by Uber on the Uber Engineering Blog on January 15, 2020. Check out eng.uber.com for more articles about Uber's engineering work and follow Uber Engineering at @UberEng and Uber Open Source at @UberOpenSouce on Twitter for updates from our teams.
Uber leverages real-time analytics on aggregate data to improve the user experience across our products, from fighting fraudulent behavior on Uber Eats to forecasting demand on our platform.
As Uber’s operations became more complex and we offered additional features and services through our platform, we needed a way to generate more timely analytics on our aggregated marketplace data to better understand how our products were being used. Specifically, we needed our Big Data stack to support cross-table queries as well as nested queries, both requirements that would enable us to write more flexible ad hoc queries to keep up with the growth of our business.
To resolve these issues, we built a solution that linked Presto, a query engine that supports full ANSI SQL, and Pinot, a real-time OLAP (online analytical processing) datastore. This married solution allows users to write ad-hoc SQL queries, empowering teams to unlock significant analysis capabilities.
By engineering full SQL support on Apache Pinot, users of our Big Data stack can now write complex SQL queries as well as join different tables in Pinot with those in other datastores at Uber. This new solution enables operations teams with basic SQL knowledge to build dashboards for quick analysis and reporting on aggregated data without having to spend extra time working with engineers on data modelling or building data pipelines, leading to efficiency gains and resource savings across the company.
Challenges
Timely, ad-hoc data analytics provide data scientists and operations teams at Uber with valuable information to make intelligent, data-driven decisions that benefit our users in real-time. Additionally, when operations teams request a metric that requires data across tables or other types of joins, engineers need to manually build a new metrics dashboard to satisfy this type of query. To facilitate this functionality in our Big Data stack, we needed a solution that could support querying near-real-time data with ad hoc ANSI SQL queries in our Apache Pinot datastores.
Presto, which is widely used at Uber, is a distributed query engine that allows users to write SQL queries to access various underlying data stores. Presto offers full SQL support, but it generally doesn’t support real-time analytical datastores in an efficient manner, instead primarily querying tables in Hadoop, where data freshness is usually several hours old.
Teams across Uber use Pinot to answer analytical queries with low query latency. However, the Pinot Query Language (PQL) lacks key functionalities, including nested queries, joins, and versatile UDF (e.g., regular expressions and geospatial functions). If users wanted to do anything more complicated, they had to spend time (upwards of several hours to a week) modeling data. Through our experience using these technologies separately, we realized that they actually complement each other quite well for conducting and storing ad-hoc data analytics. While Presto supports SQL, users cannot use it to access fresh aggregated data, and though Pinot can provide second-level data freshness, it lacks flexible query support. These discoveries are outlined in Figure 1, below:
| Query Engine | Presto | Pinot |
|---|---|---|
| Query latency | Seconds to minutes | Millisec to seconds |
| Query syntax | Flexible (ANSI-SQL) | Limited (no join, Limited UDF) |
| Data freshness | Hours for derivative tables 10 min to > 1 hour for raw tables | Seconds |
Figure 1. Comparing Presto and Pinot’s query latency, query syntax, and data freshness reveals that these two query engines have compatible strengths. In terms of query latency, Presto lags behind at seconds to minutes, while Pinot excels, providing answers within milliseconds to seconds. On the other hand, Presto’s ANSI SQL is much more flexible, while Pinot’s query syntax is restricted by its lack of joins and limited UDF. Presto may return data that’s over an hour old to queries, while Pinot’s data refreshes in seconds.
Our solution
We engineered a solution that allows Presto’s engine to query Pinot’s data stores in real time, optimized for low query latency. Our new system utilizes the versatile Presto query syntax to allow joins, geo-spatial queries, and nested queries, among other requests. In addition, it enables queries of data in Pinot with a freshness of seconds. With this solution, we further optimized query performance by enabling aggregate pushdown, predicates pushdown, and limit pushdown, which reduces unnecessary data transfer and improves query latency by more than 10x.
This solution enabled greater analytical capabilities for operations teams across Uber. Now, users can fully utilize the flexibility of SQL to represent more complex business metrics, and render query results into a dashboard using in-house tools. This capability has improved our operations efficiency and reduced operations cost.
Architecture
While designing our new system, we first had to consider how we would modify Presto’s engine. A Presto cluster has two types of components: a coordinator and its workers. The coordinator is in charge of query parsing, planning, task scheduling, and distributing tasks to its group of workers. When the coordinator gives its workers an assignment, the workers fetch data from data sources through connectors and return the final result to the client.
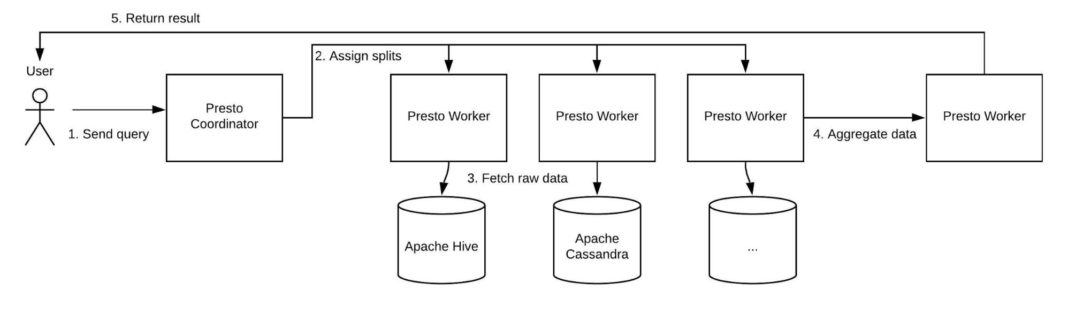
Figure 2. Uber’s Presto architecture incorporates one coordinator node and several worker nodes. After the coordinator receives and processes the query, it generates a query plan and distributes the tasks to its workers. Each worker scans a table scan from the underlying storage and sends the aggregated insights back to the user.
As shown in Figure 2, above, Presto supports plugging in different storage engines, and allows the connector in each worker to fetch data from the underlying storage. Then, since Pinot can be used as storage, we can write a Pinot connector that supports fetching Pinot data through Presto workers.This functionality makes it possible to query Pinot data through Presto.
Before building the Pinot connector, it’s important to understand how Pinot works. A Pinot cluster has three main components: controllers, brokers, and servers. While controllers are in charge of node and task management, servers store and serve data. Each server contains a list of segments (in other words, shards) and each segment is a set of rows. Brokers receive queries, fetch data from servers, and return the final results to clients. Pinot servers can ingest data from Apache Kafka, a distributed real-time streaming platform, and the data can be queried as it is ingested, so the data freshness can be on the order of seconds.
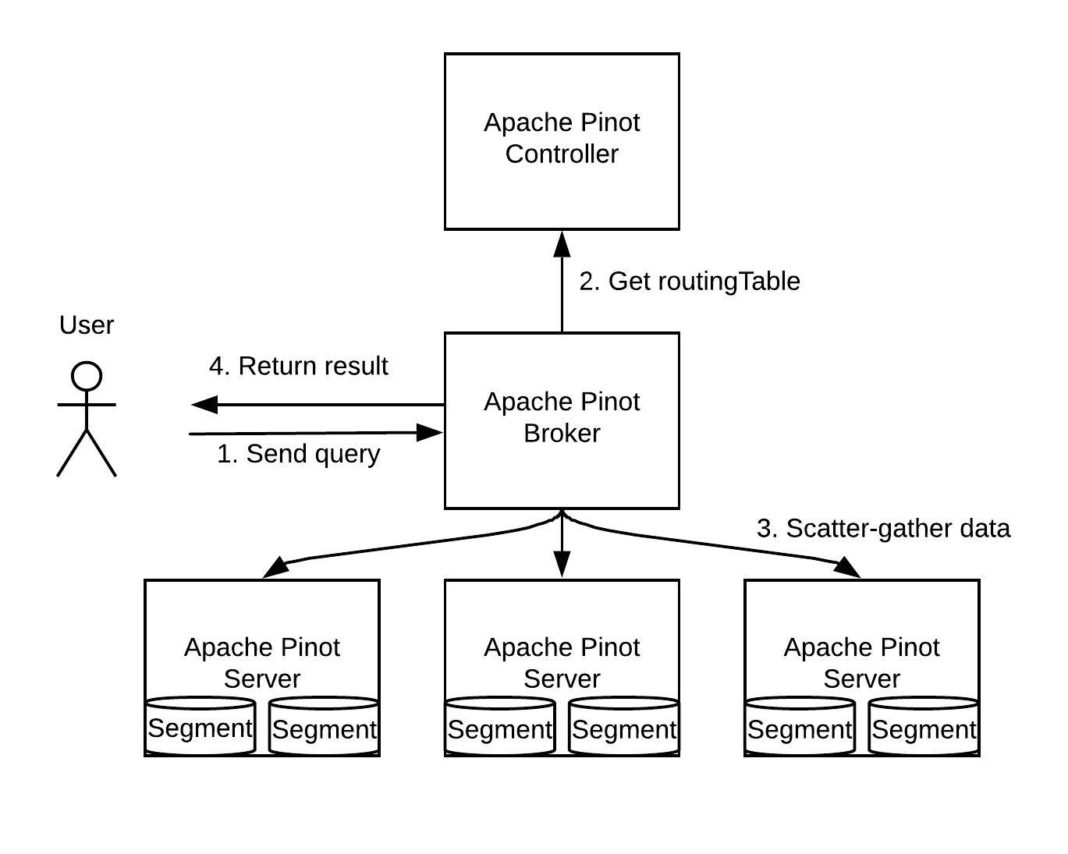
Figure 3. The Pinot architecture incorporates controllers, brokers, and servers. When the broker receives the query from the user, it receives a routing table from the controller. The routing table informs the broker where different segments are stored. The broker then fetches data from different servers in a scatter-gather manner, and finally returns the merged result.
As shown in Figure 3, above, Pinot servers store different partitions of the data, and after getting data from each server, the broker merges the data and returns the final result. This workflow is similar to the Presto architecture, in which different workers fetch data before sending it to the aggregation worker. Based on Pinot’s data processing flow, building a Pinot connector in Presto seemed like a viable option for us.
Marrying Presto with Pinot
To merge the intuitive interface of Presto with the swift power of Pinot, we built a novel Pinot connector in Presto that allows Presto to query data with minimal latency, facilitating the complex queries of Presto's SQL support.
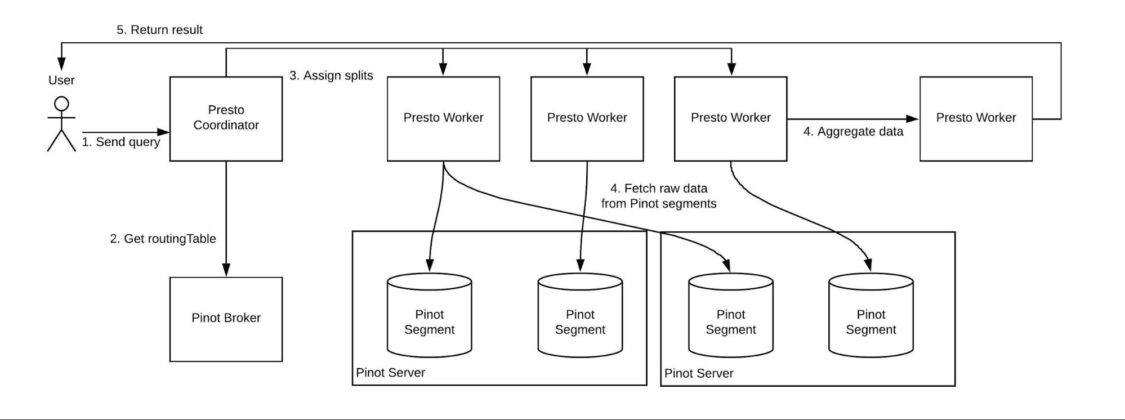
Figure 4. Architecture of Presto-Pinot Connector. After the Coordinator receives the query from the user, it gets the routing table from the Pinot broker to find where each Pinot segment is stored. Then, it generates splits for each Presto worker to fetch Pinot data from the corresponding Pinot segments. Another Presto worker would aggregate the fetched data and return the final result to the user.
As depicted in Figure 4, above, we combined Pinot’s scatter-gather query mode with Presto’s coordinator-worker architecture. When a user sends a Presto query for Pinot data with this new solution, Presto’s coordinator queries the Pinot broker to access Pinot’s routing table. The routing table contains information about which Pinot segments are stored on which Pinot servers. Next, Presto creates splits based on the routing table. The splits tell each worker a list of Pinot segments from which it should fetch data. Subsequently, each Presto worker simultaneously queries the underlying Pinot data in its assigned split, enabling aggregation and predicate pushdown when applicable. Finally, the aggregation worker aggregates the results from each split and returns the final result back to the user.
Our initial Pinot connector
Our initial version of the Pinot connector treated Pinot as a database. Other open source Presto connectors, such as Presto-Cassandra, a Cassandra connector that allows querying Apache Cassandra through Presto, and Presto-Hive, a Hive connector that allows querying data in HDFS through Presto, operate this way, too.
Improving query performance
After implementing the initial workflow, we discovered that our system was spending most of its query execution time on data transfer, especially as the data volume of the Pinot tables grew. A lot of data transferred by workers was discarded by the aggregation worker, and fetching unnecessary data both increased query latency and added extra workload for Presto workers and Pinot servers.
To address these issues and improve query performance, we implemented the following updates to our system:
Predicate pushdown
Predicates are Boolean-valued functions in the WHERE clause of the query. Predicates represent the allowed value range for specific columns. We implemented predicate pushdown, which means that the Presto coordinator would push the predicate down to Presto workers to do best-effort filtering when fetching data from Pinot. When Presto workers fetch records from Pinot servers, our system preserves the predicates of the query the workers are operating with. By applying the predicates in the user’s query in the Presto workers, our system fetches only the necessary data from Pinot. For example, if the predicate of the Presto query is WHERE city_id = 1, utilizing predicate pushdown would ensure that workers only fetch records from Pinot segments where city_id = 1. Without predicate pushdown, they will fetch all data from Pinot.
Limit pushdown
We also implemented a limit pushdown for our system in order to further prevent unnecessary data transfer. Often, users do not need to query all rows of data in a given table, and this new functionality enables users to explore data on a much more limited (and less resource-intensive) scale. For instance, a user may only want to view the first ten rows of Pinot data; with this feature, the user can add LIMIT 10 in the query to sample just ten rows of the data. By applying limit pushdown, we ensure that when there are limit clauses (e.g., LIMIT 10) in the Presto query, we can apply the same limit when Presto workers fetch data from Pinot, preventing them from fetching all records.
Aggregate pushdown
Since many users apply aggregates like SUM/COUNT in their analytics queries, our new system facilitates aggregate pushdowns when relevant, allowing Pinot to perform various aggregations, including COUNT, MIN, MAX, and SUM.
The queries that users send to Presto coordinators already include aggregation requests. In order to provide aggregate pushdown, we pass this information to connectors with what we call aggregation hints. These are generated after query parsing and indicate the aggregations requested in each column. Then, when Presto workers fetch data from Pinot, they directly request the aggregated values and process them accordingly.
Due to aggregate pushdown, our current system can:
Utilize the functionality of Pinot to support aggregational queries with low query latency using Star-Tree.
Reduce the number of rows needed from thousands to just one when passing aggregated results like COUNT and SUM from the Pinot server to Presto workers as one entry, greatly reducing query latency.
Dramatically improve query performance by more than 10x, due to the reduction of the amount of data transferred between Presto workers and Pinot servers.
With the benefits of aggregate pushdown to reduce query latency fresh in our minds, let’s take a deeper look at how we engineered our system to enable aggregate pushdown for common aggregate functions.
Pushing down MIN/MAX/SUM
Aggregations like MIN, MAX, and SUM are relatively straightforward to push down: we simply rewrite the Pinot query with the actual aggregation, so instead of fetching records, we can just request the MIN/MAX/SUM value in each split and get the result in one single row. In Presto’s architecture, each split returns a page which represents the data fetched from underlying storage. When the Presto aggregation worker processes this page, it treats each row in it as a record.
For example, imagine the Presto worker queries a Pinot segment with three records: 1, 10, and 100. Suppose the user wants to query the MAX of those records. When aggregate pushdown is not enabled, the Presto worker returns a page with three records: 1, 10, and 100. The aggregation worker computes the MAX of 1, 10, and 100, and returns 100 to the user. With aggregate pushdown, the Presto worker requests the MAX value directly from Pinot, and returns a page with one record of 100. The aggregation computes the max of 100 and returns the result to the user.
In Figure 5, below, we depict the workflow of the original Pinot connector, and in Figure 6, below, we compare it to our updated version of the tool:
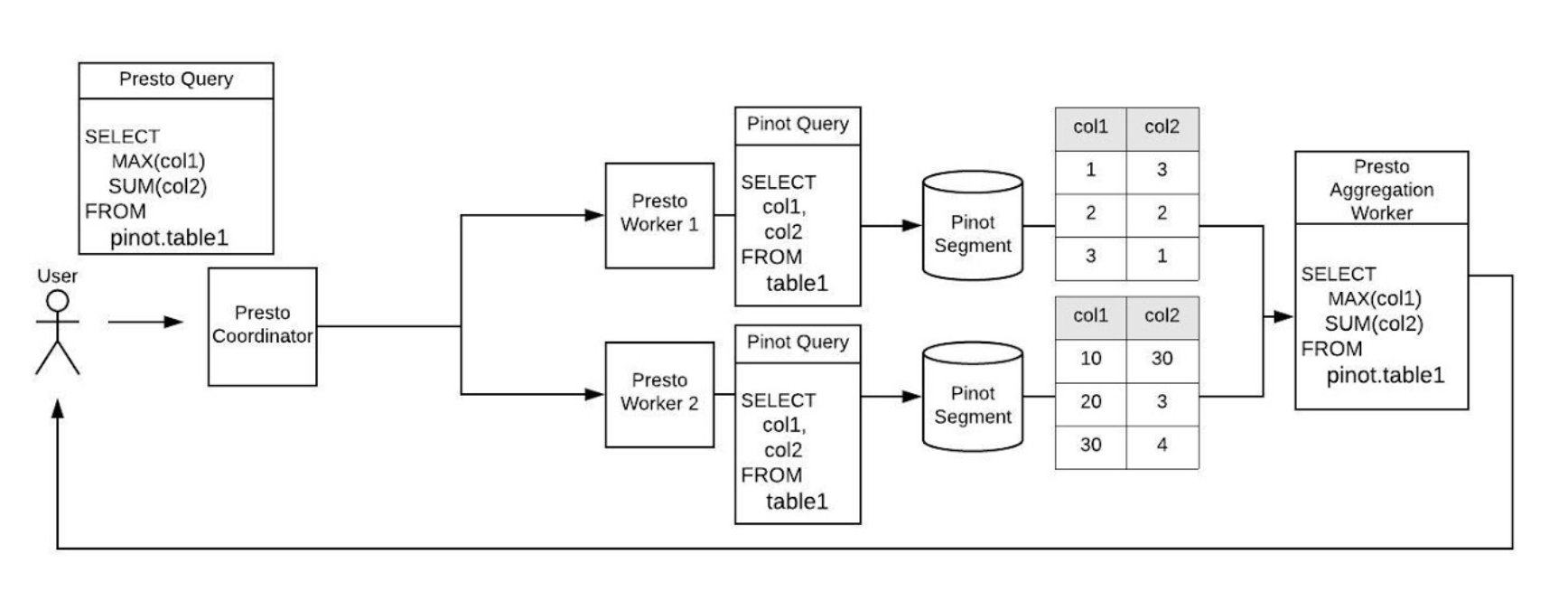
Figure 5. The original Pinot connector without aggregate pushdown received the query with aggregate functions (MAX and SUM). Each Presto worker fetches data from Pinot and constructs a page with all matching rows. The Presto aggregation worker then returns the aggregated results to the user.
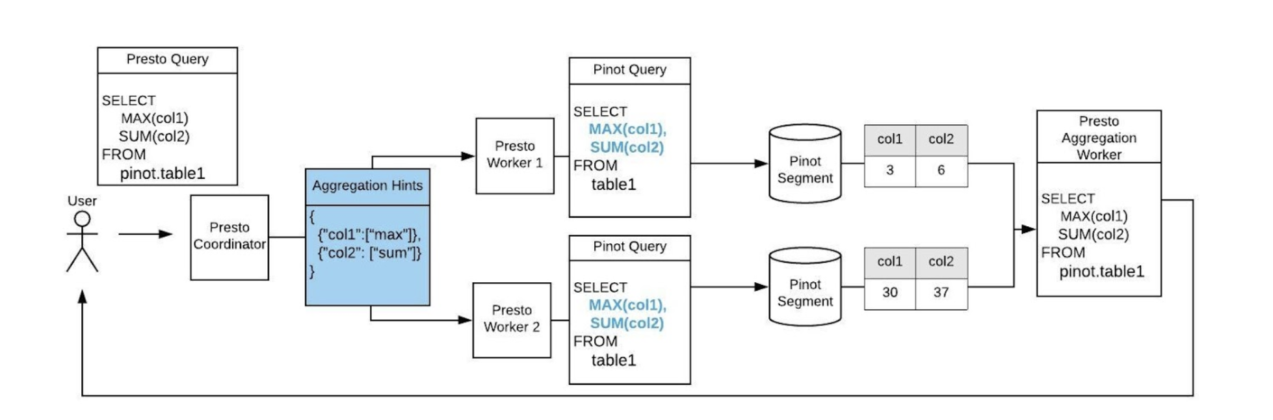
Figure 6. The Pinot connector that supports aggregate pushdown (MIN, MAX, and SUM) passes the query with aggregate functions (MAX and SUM) to workers regarding which columns to aggregate on. Each worker will directly fetch the aggregated values (MAX and SUM) from Pinot, and construct a page with one value per aggregated column. The Presto aggregation worker then aggregates the returned rows and returns the final result to the user.
As depicted in Figure 6, Presto workers in the revised Presto workflow now only fetch one row per segment instead of thousands of rows by utilizing more information from the original query about the requested aggregate functions. As a result, network transfers are significantly reduced between Presto workers and Pinot servers.
Pushing down COUNT
Pushing down COUNT was not as simple as pushing down MIN, MAX, and SUM queries. Our initial architecture for the solution would not facilitate this query, and would pull inaccurate results. For instance, if our Pinot segment contained three values, 1, 10, and 100, pushing down COUNT in Pinot would return one row with a value of 3, indicating that there are three rows matching the original query. When Presto’s aggregation worker processed this page, it ignored whatever value was in that row, treated it as one row, and performed the COUNT, so the final result would be 1 instead of 3, the correct answer.
In order to solve this problem, we refactored the Presto page so that it can represent an aggregated page, and then refactored the page construction and processing flow accordingly. The refactored architecture not only gave Presto workers the flexibility to directly construct an aggregated page, but also enabled us to push down COUNT aggregation and support other more complex aggregations (like GROUP BY) in Presto as well.
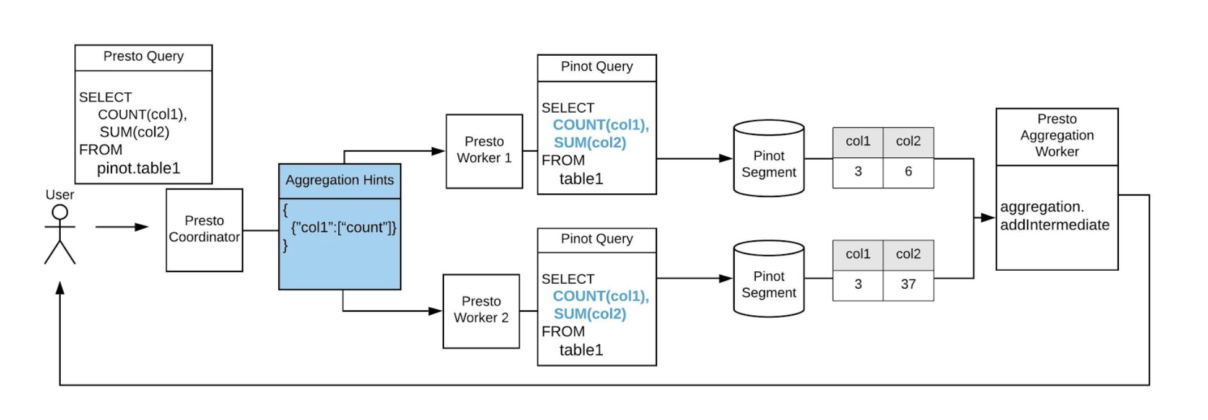
Figure 7. When the Presto connector receives the query with aggregate functions (COUNT/SUM), it will pass the information to workers on which columns to aggregate on. Each worker will directly fetch the aggregated values (COUNT/SUM) from Pinot, and construct a page with the one value per aggregated column, indicating the value is aggregated and should be directly used. The Presto aggregation worker would then directly merge each page and return the final result to the user.
We have seen tremendous query latency improvements after introducing aggregate pushdown, which greatly reduced the time users waited for their query results, thus improving developer efficiency.
How our Presto-Pinot connector performs
To evaluate how well our new system works, we benchmarked query performance on Pinot data. We generated about 100 million rows in Parquet, ORC, and Pinot segments.
We set up Presto and Pinot clusters on the same SSD box (32 core Intel Xeon CPU E5-2620 v4 @ 2.10GHz, 256GB memory). Then we ran Presto queries to request data from Parquet and ORC on the local disk through our Presto-Hive connector, as well as querying Pinot data through our new Presto-Pinot connector. We also queried Pinot data through the Pinot broker directly.
Querying Pinot directly achieved the best query latency, as we expected. When querying through Presto, we found no significant performance differences between different data sources. We saw sporadic latency spikes when querying Parquet files, and other than that, querying Pinot had similar query latencies compared with querying Parquet and ORC files through the Hive connector.
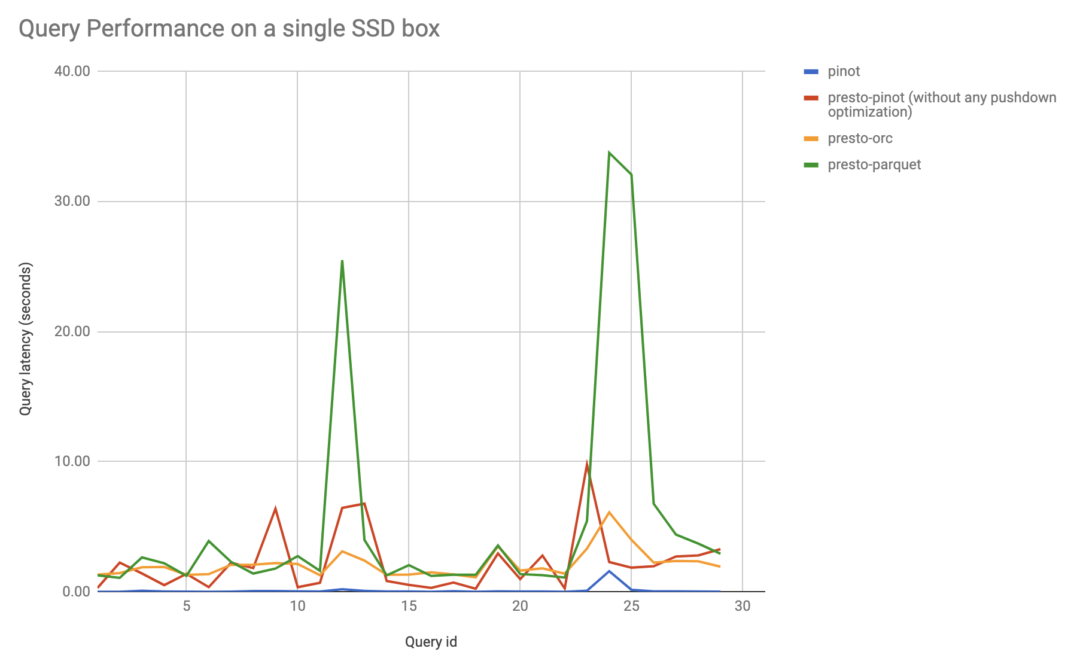
Figure 8. Query performance of querying Pinot directly vs. using Presto to query local Parquet/ORC files and Pinot segments. Querying Pinot directly achieved the lowest query latency. We observed no significant differences between querying Pinot through the Pinot connector and querying local Parquet and ORC files through the Presto connector. Note that the Pinot connector benchmarked here did not enable any pushdown optimization.
We also benchmarked how aggregate pushdown performance improved by sending aggregation queries on several Pinot tables with different sizes. As shown in Figure 9, below, our efficiency gains from aggregate pushdown grow as the total number of documents increases in the Pinot table.
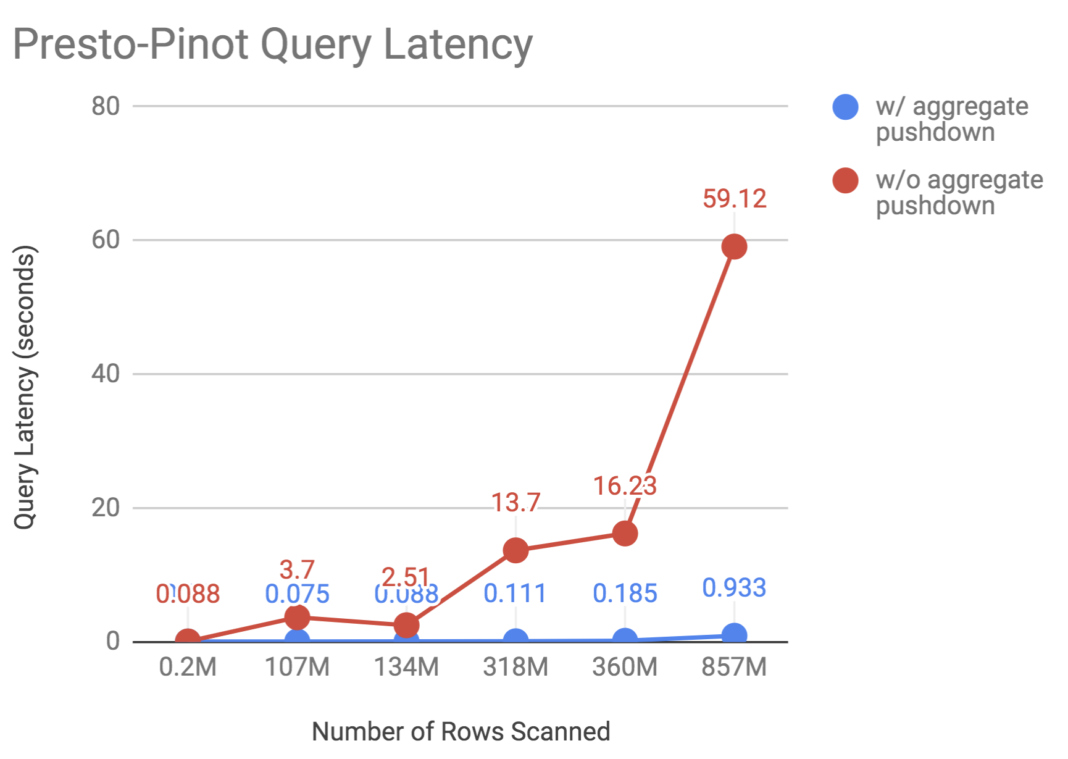
Figure 9. Query performance of Presto-Pinot connector, before and after enabling aggregate pushdown. As the total number of documents increased in the Pinot table, our efficiency gains from aggregate pushdown grew.
As shown in Figures 8 and 9, the Presto-Pinot connector had similar query performance with the existing Hive connector, while providing improved data freshness over Parquet or ORC files in HDFS. After further introducing aggregate pushdown in the Pinot connector, we were able to utilize the analytical capability of Pinot to do certain commonly used aggregates, which enhanced query latency. By allowing users to access fresh data in Pinot with SQL queries in Presto, the Pinot connector unlocks even more precise and data-driven business decisions. In turn, these decisions allow us to deliver a better user experience across our suite of products.
Looking ahead
With the success of our Presto-Pinot connector, we’ve seen just how valuable it is to access fresh data with standard SQL. Without having to learn different SQL dialects for different real-time data storage systems, users can access the fresh insights they need and make informed decisions. To this end, we are currently building the next generation of our analytics platform by consolidating storage solutions and using Presto as our unified query layer.
Acknowledgements
We’d like to give a special thanks to Xiang Fu, Zhenxiao Luo and Chinmay Soman for their valuable contribution to this project.
Learn more about how we engineer real-time analytics at Uber: