Data Lake Analytics: Alibaba's Federated Cloud Strategy
Presto is known to be a high-performance, distributed SQL query engine for Big Data. It offers large-scale data analytics with multiple connectors for accessing various data sources. This capability enables the Presto users to further extend some features to build a large-scale data federation service on cloud.
Alibaba Data Lake Analytics embraces Presto’s federated query engine capability and has accumulated a number of successful business use cases that signify the power of Presto's analytics capability.
Data Federation Service
Today’s cloud databases empower cloud users to easily and directly interact with other cloud products and services, available to be built for their own cloud data lake analytic scenarios and solutions. The architecture to pile up a cloud-based data lake analytic scenario is divided into three layers:
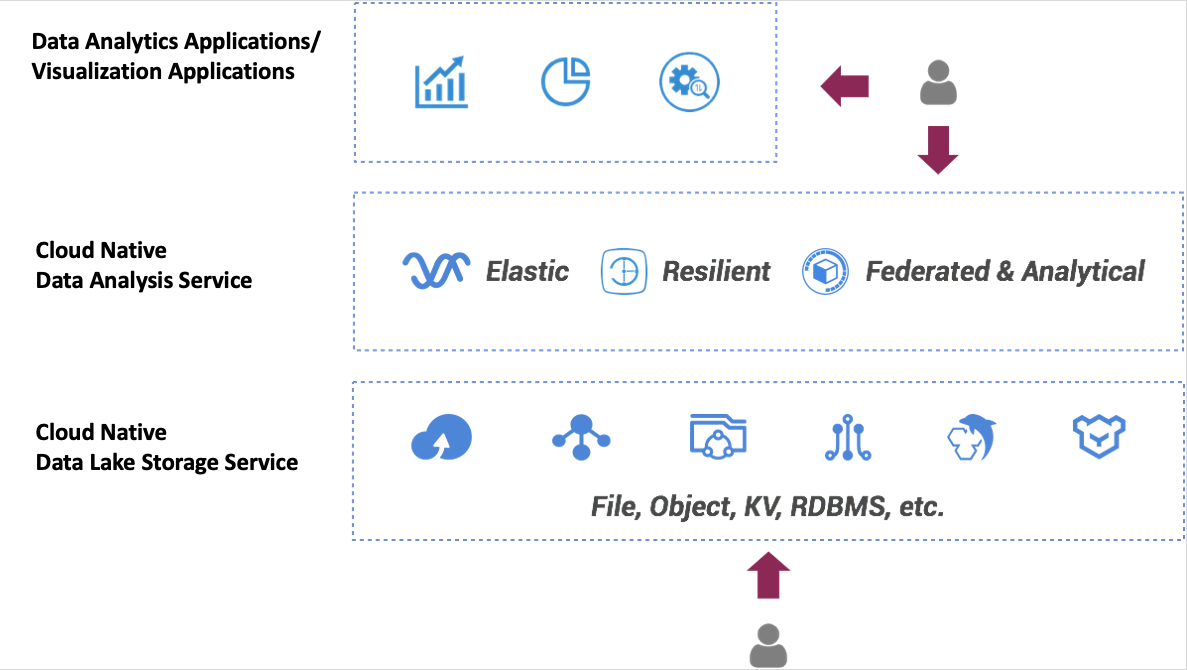
First Layer: A variety of selected cloud native data storage and database services.
Users store and place their data on a series of cloud-native data storage services and cloud databases systems. Cloud data sources vary depending on different business use cases and business scenarios, but speaking in general, there are two cloud data storage approaches: NoSQL and relational databases. Various choices of storage service may include: cost-effective object cloud storage which may store files, structured, semi-structured, unstructured raw data, multimedia files; NoSQL, RDS, and other cloud database services;
Second Layer: Cloud native data lake analysis service layer.
This layer emphasizes a very important feature in Cloud Native computing, that is, Serverless is server-free and is the basic service for building SaaS on the cloud, except for Data Lake analysis scenarios, there is also a more ubiquitous serverless PaaS and Function-computing as-a-Service (FaaS) such as Alibaba Cloud Function Calculation. This article focuses on the serverless analysis capability of Data Lake analytic scenarios.
Elasticity - This allows an on-demand flexibility capability, which means being flexible in time, predictable and intelligent mixed load handling ability
Resiliency - This is a typical feature for High Availability systems. When failures occurs, the failover process moves processing performed by the failed component to the backup component within a matter of microseconds. This mechanism becomes transparent to users for a better user experience in a HA system in both Rolling Upgrade and Disaster Recovery across AZ (availability zones)
Federated and Analytical - Multi-mode federated analysis capabilities, includes analysis and integration capabilities for multiple formats and systems, comprehensive analysis functions and excellent interactive analysis performance and experience, parallel computing processing capabilities, compatible interface capability and so on.
Third layer: Data analysis application and visualization application layer
Business logic based upon Data Lake analysis service layer may require an integration of data analysis tools on the cloud. All kinds of visualized data analysis products and tools are available to be interacted with users.
Upon the basis of the above cloud data lake analysis architecture, the data federation ecosystem is divided into three layers accordingly, for which Data Lake Analytics plays a key role for serverless cloud-native computing framework:
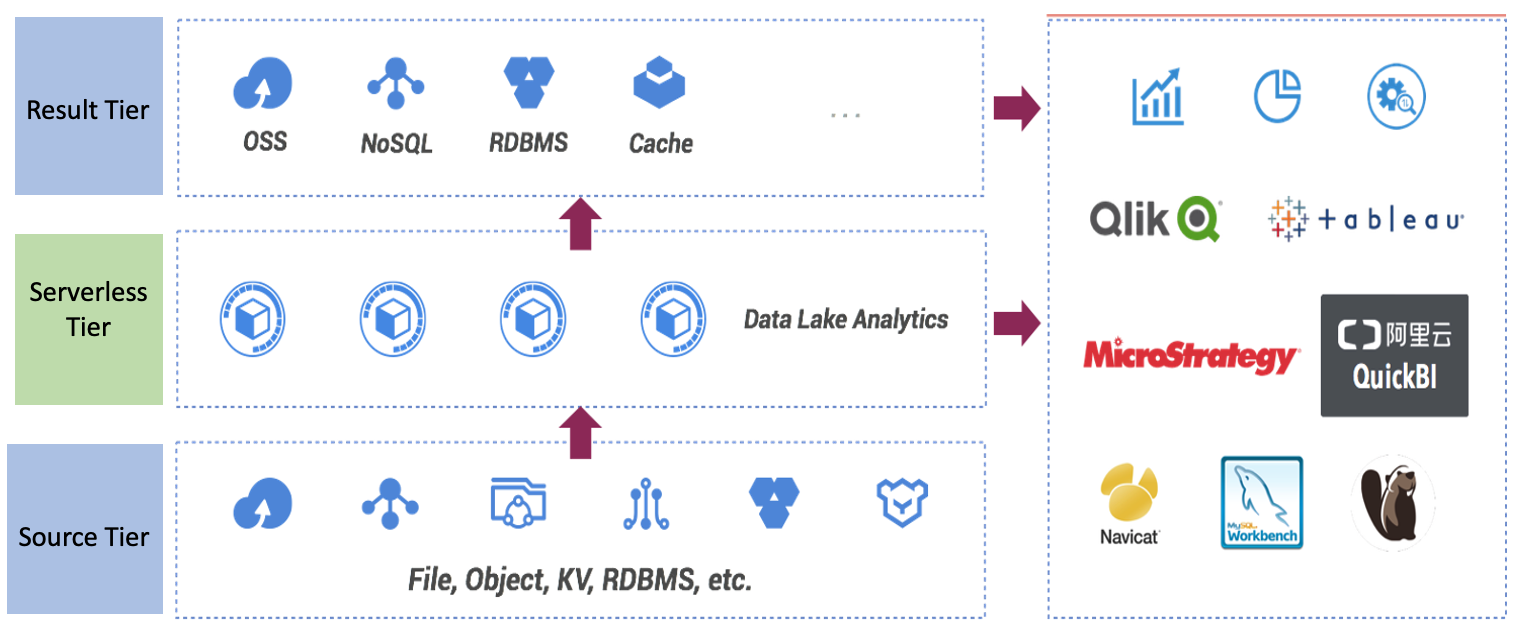
Data Lake Analytics
Introducing DLA
Data Lake Analytics, known as DLA, is a large scale serverless data federation service on Alibaba Cloud. It is one of the most popular serverless SQL engines based on a well-customized computing engine from PrestoDB. DLA integrates with mainstream data sources and provides easy-to-use MySQL JDBC/ODBC connection protocol to allow users to interact with.
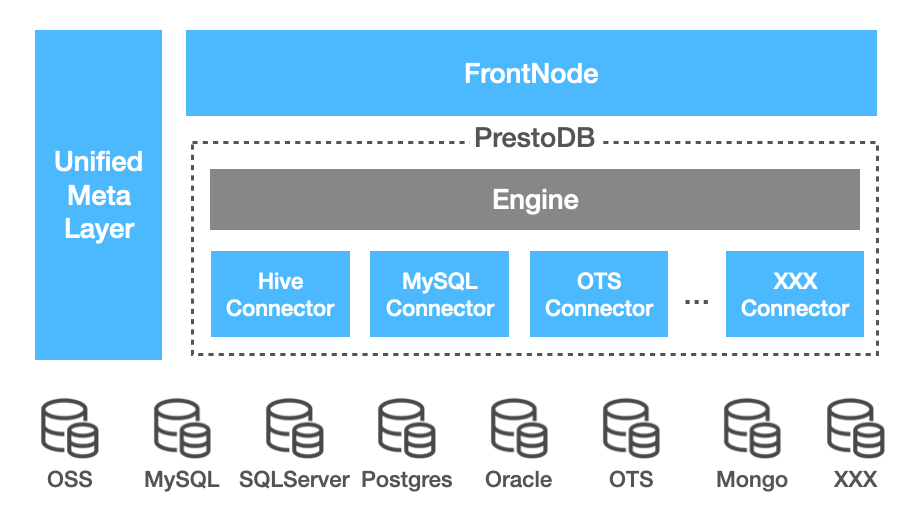
FrontNode is the SQL access layer which provides MySQL protocol to let users interact with. MySQL is a flexible and compatible connection protocol service, frequently used by DLA users. Unified Meta Layer is a metadata repository which holds all metadata for all data sources DLA can support. DLA is running as an independent project which was forked from PrestoDB(0.227) and is now integrated with mainstream data sources in Alibaba Cloud. It is currently working closely with the PrestoDB community to track ongoing projects and updates. It is mission critical to continue the close partnership with PrestoDB for business success with latest updates.
DLA Product Key Features:
- Serverless
a. No infrastructure and management cost
b. Zero start-time
c. Transparent upgrade
d. QoS Elastic Service - Standard SQL Connections
a. Compatible with standard SQL Compliance
b. Rich built-in function support
c. JDBC/ODBC support
d. Compatible with BI tools - Heterogeneous Data Sources
a. Enable OSS Data analysis requirements
b. Enable Table Store Data for SQL querying service
c. Federated data analysis across multiple database instances
d. Ease of interconnection analysis for multiple data sources
e. Any forms of analytics in “Data Lake” - Optimized Compute Engine
a. Support for unstructured data
b. Vectorized execution and optimization
c. Operator pipeline optimization
d. Resource isolation and prioritization
DLA Use Cases
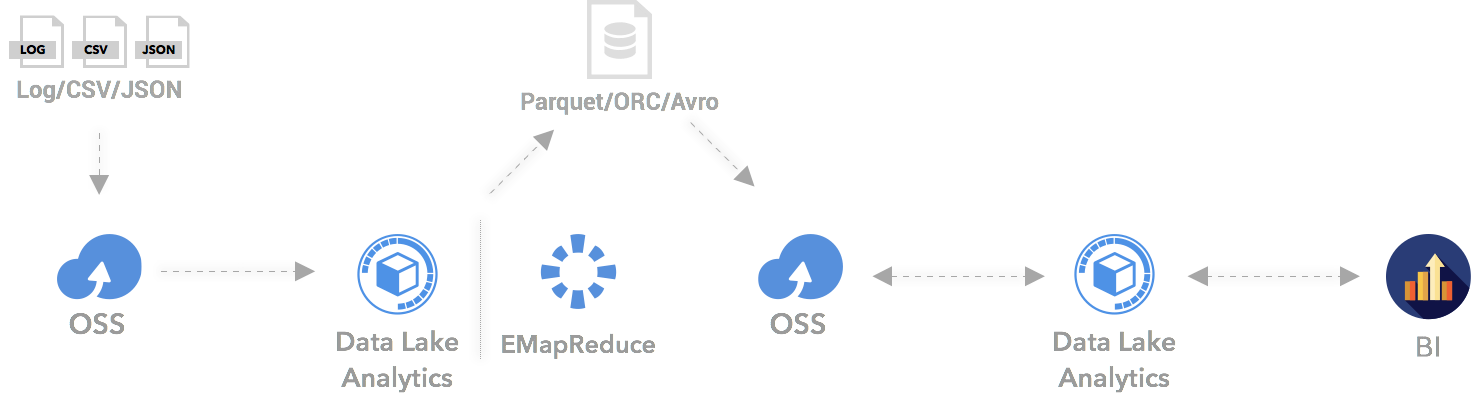
Typical Data Flow Scenarios:
Generally DLA empowers cloud users analytic capability in 3 typical user data flow scenarios:
- The cloud user uploads the business generated data such as Log, CSV, JSON and other files, directly to OSS (AliCloud Object Storage Service), and then uses DLA to directly point to the file or folder for which the table is created to query. Then the user may use BI tools to analyze and visualize business data analytics.

- The cloud user can directly copy and upload data to OSS, and then use DLA to directly point files or folders for which the table is created to query. Common data formats like Parquet, ORC, RCFile, Avro, and others are supported as well. Then the user may use BI tools for business data analysis and visualization.

- In order to provide better query performance and low storage cost for subsequent data analysis on OSS, data can be converted into Parquet or ORC format to improve the cost performance of repeated data analysis.
Alibaba Use Case Studies:
Customer Case #1: Log Data Analytics
Cloud customers generate log data which is stored on OSS. The challenge is that those log data are unstructured and typically on the order of Petabytes of data size.
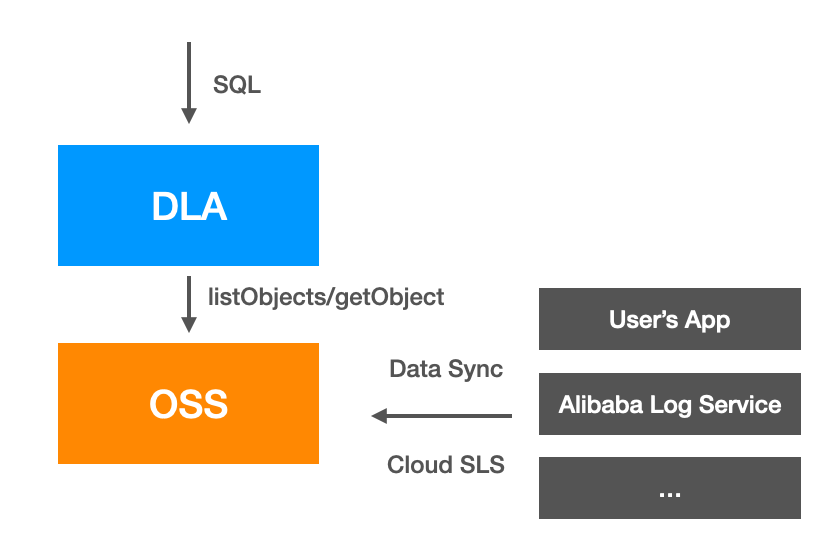
So in order to make it available to analyze, DLA’s massive parallel processing engine is the key to business success. It allows users to do full-volume, personalized log data analysis by using DLA’s Hive connector. Additionally log data can be synchronized to OSS with a max delay of 5 minutes with Alibaba Cloud SLS that can feed data to DLA in near real-time.
Customer Case #2: Genetic Data Analytics
One of Alicloud’s data vendors is in the Genetic engineering industry. The data volume is gigantic and the data is stored in various data sources. This is raw bioinformatics data storing gene sequence variations in the Variant Call Format(VCF). The challenge is that Genetic datasets are huge, but still need to be analyzed promptly.
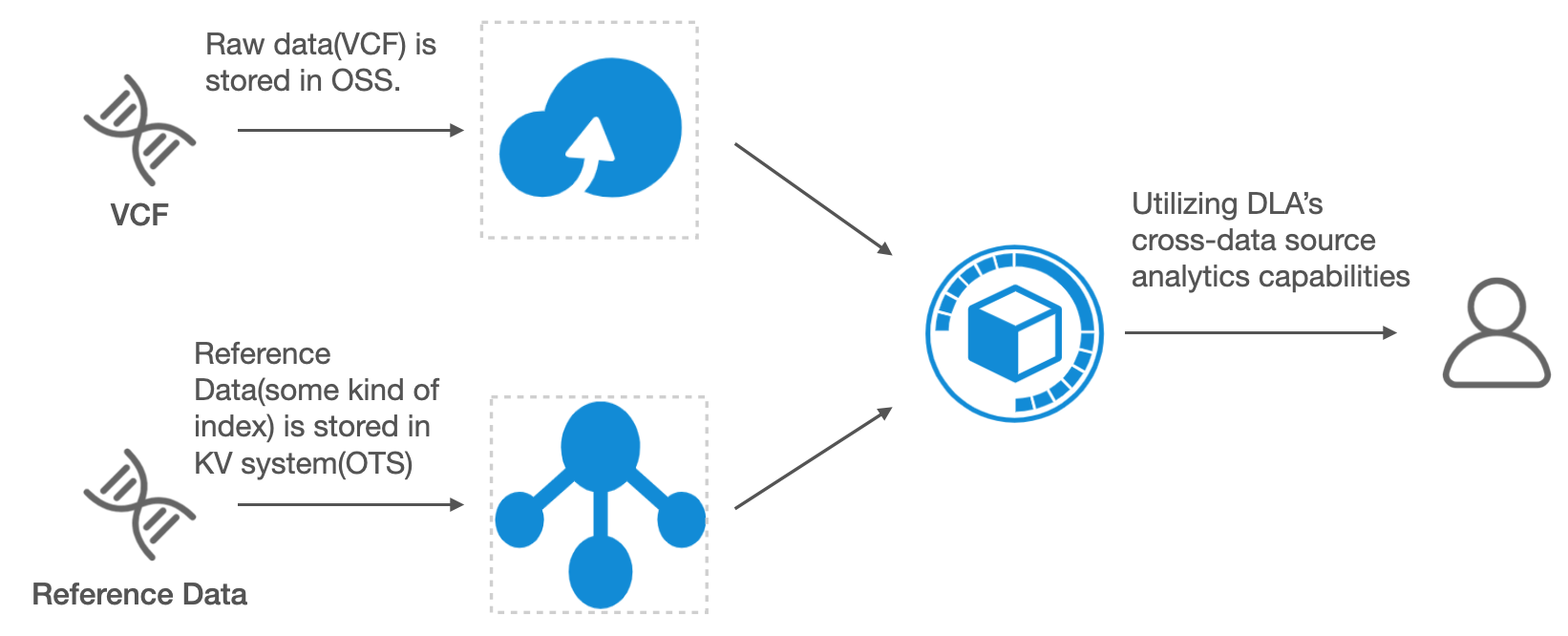
The solution is to place a huge volume gene data on OSS where storage costs are low and materialize indexing data to a Key value store system. Aliyun Open Table Service (OTS) is a distributed NoSQL database that works well for this propose. DLA's cross data source analytic capabilities can then be used to join the data together across services making it possible to quickly access and analyze the data even on large scale datasets.
Conclusion
Alibaba Data Lake Analytics embraces Presto’s federated query engine capability and has empowered many Alibaba cloud users to experience large scale serverless cloud service. DLA is working to make the cloud user experience more transparent by improving ease of use and reducing infrastructure management overhead. The next blog will discuss some key technical developments on top of the Presto codebase.