Running Presto in a Hybrid Cloud Architecture
Migrating SQL workloads from a fully on-premise environment to cloud infrastructure has numerous benefits, including alleviating resource contention and reducing costs by paying for computation resources on an on-demand basis. In the case of Presto running on data stored in HDFS, the separation of compute in the cloud and storage on-premises is apparent since Presto’s architecture enables the storage and compute components to operate independently. The critical issue in this hybrid environment of Presto in the cloud retrieving HDFS data from an on-premise environment is the network latency between the two clusters.
This crucial bottleneck severely limits performance of any workload since a significant portion of its time is spent transferring the requested data between networks that could be residing in geographically disparate locations. As a result, most companies copy their data into a cloud environment and maintain that duplicate data, also known as Lift and Shift. Companies with compliance and data sovereignty requirements may even prevent organizations from copying data into the cloud. This approach is not scalable and requires introducing a lot of manual effort to achieve reasonable results. This article introduces Alluxio to serve as a data orchestration layer to help serve data to Presto efficiently, as opposed to either directly querying the distant HDFS cluster or manually providing a localized copy of the data to Presto in a cloud cluster.
Hybrid Cloud Architecture with Alluxio and Presto
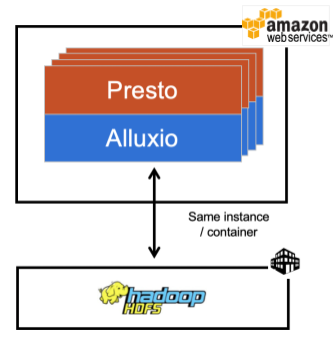
In the following architecture diagram, both Presto and Alluxio processes are co-located in the cloud cluster. As far as Presto is concerned, it is querying for and writing data to Alluxio as if it were a co-located HDFS cluster. When Alluxio receives a request for data, it fetches the data from the remote HDFS cluster initially, but subsequent requests will be served directly from its cache. When Presto sends data to be persisted into storage, Alluxio asynchronously writes data to HDFS, freeing the Presto workload from needing to wait for the remote write to complete. In both read and write scenarios, with the exception of the initial read, a Presto workload is able to run at the same, if not faster, performance as if it were in the same network as the HDFS cluster. Note that besides the deployment and configuration of Alluxio and establishing the connection between Presto and Alluxio, there is no additional configuration or other manual efforts needed to maintain the hybrid environment.
Benchmarking Performance
For benchmarking, we run SQL queries on data in a geographically separated Hive and HDFS cluster.
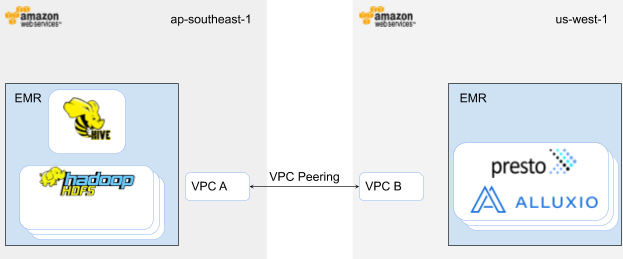
The hybrid cloud environment used for experimentation in this section includes two Amazon EMR clusters in different AWS regions. Because the two clusters are geographically dispersed, there is noticeable network latency between the clusters. VPC peering is used to create VPC connections to allow traffic between the two VPCs over the global AWS backbone with no bandwidth bottleneck. Readers can follow the tutorial in the whitepaper to reproduce the benchmark results if using AWS as the cloud provider.
We used data and queries from the industry standard TPC-DS benchmark for decision support systems that examines large amounts of data and answers business questions. The queries can be categorized into the following classes (according to visualizations in this repository): Reporting, Interactive, and Deep Analytics.
With Alluxio, we collected two numbers for all TPC-DS queries; denoted by Cold and Warm.
- Cold is the case where data is not loaded in Alluxio storage before the query is run. In this case Alluxio fetches data from HDFS on-demand during query execution.
- Warm is the case where data is loaded into Alluxio storage after the Cold run. Subsequent queries accessing the same data do not communicate with HDFS.
With HDFS, we collected two numbers as well; Local and Remote.
- Local is the case where Presto and HDFS are co-located in the same region. This number shows us the performance of running the compute on-premises when data is local without bursting into the cloud.
- Remote is the case where Presto reads from storage in another region.
TPC-DS Data Specificiations
| Scale Factor | Format | Compression | Data Size | Number of Files |
|---|---|---|---|---|
| 1000 | Parquet | Snappy | 463.5 GB | 234.2 K |
EMR Instance Specificiations
| Instance Type | Master Instance Count | Worker Instance Count | Alluxio Storage Volume (us-west-1) | HDFS Storage Volume (ap-southeast-1) |
|---|---|---|---|---|
| r5.4xlarge | 1 each | 10 each | NVMe SSD | EBS |
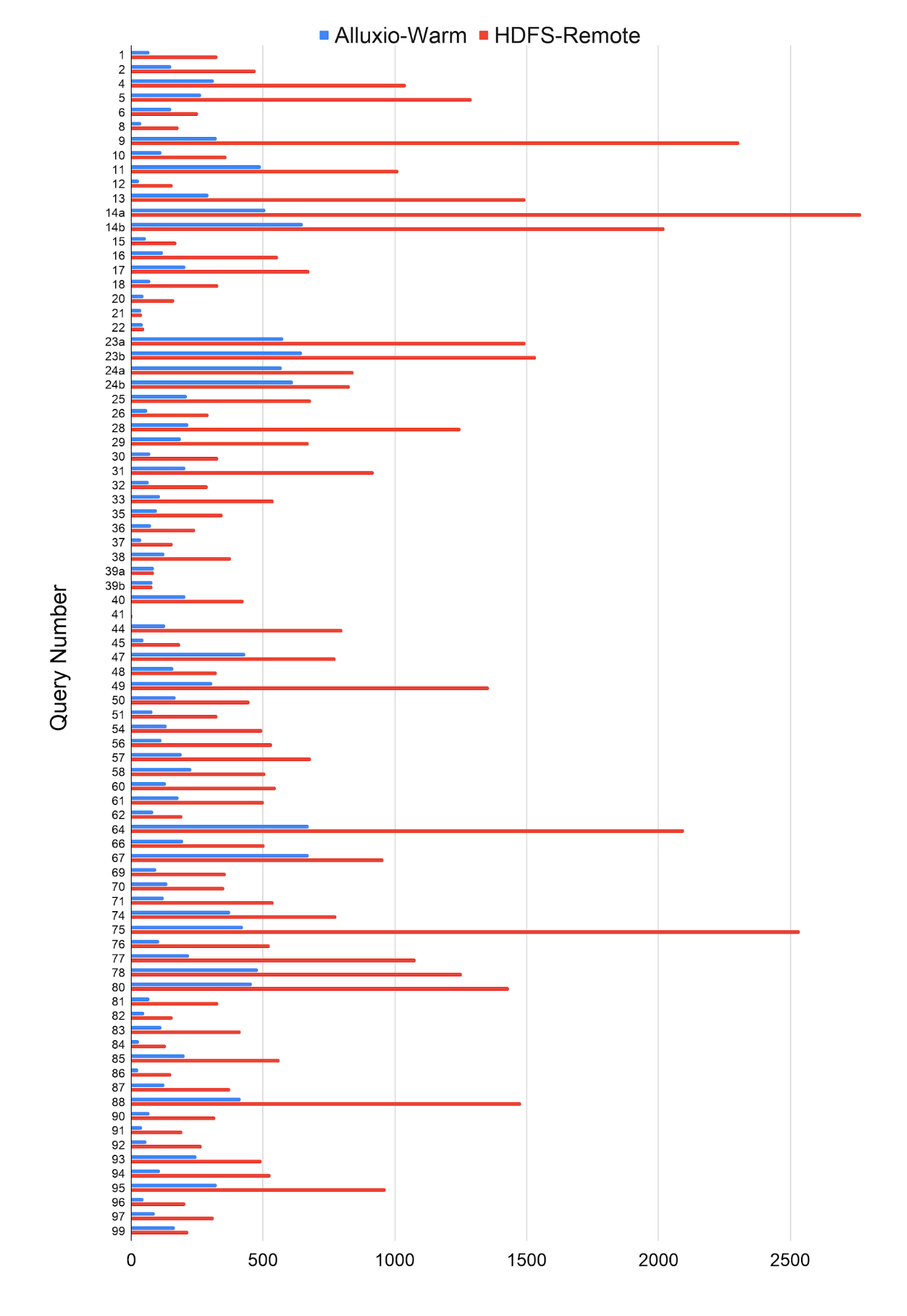
We compared the performance of Presto with Alluxio (Cold and Warm) with Presto directly on HDFS (Local and Remote). Benchmarking shows an average of 3x improvement in performance with Alluxio when the cache is warm over accessing HDFS data remotely.
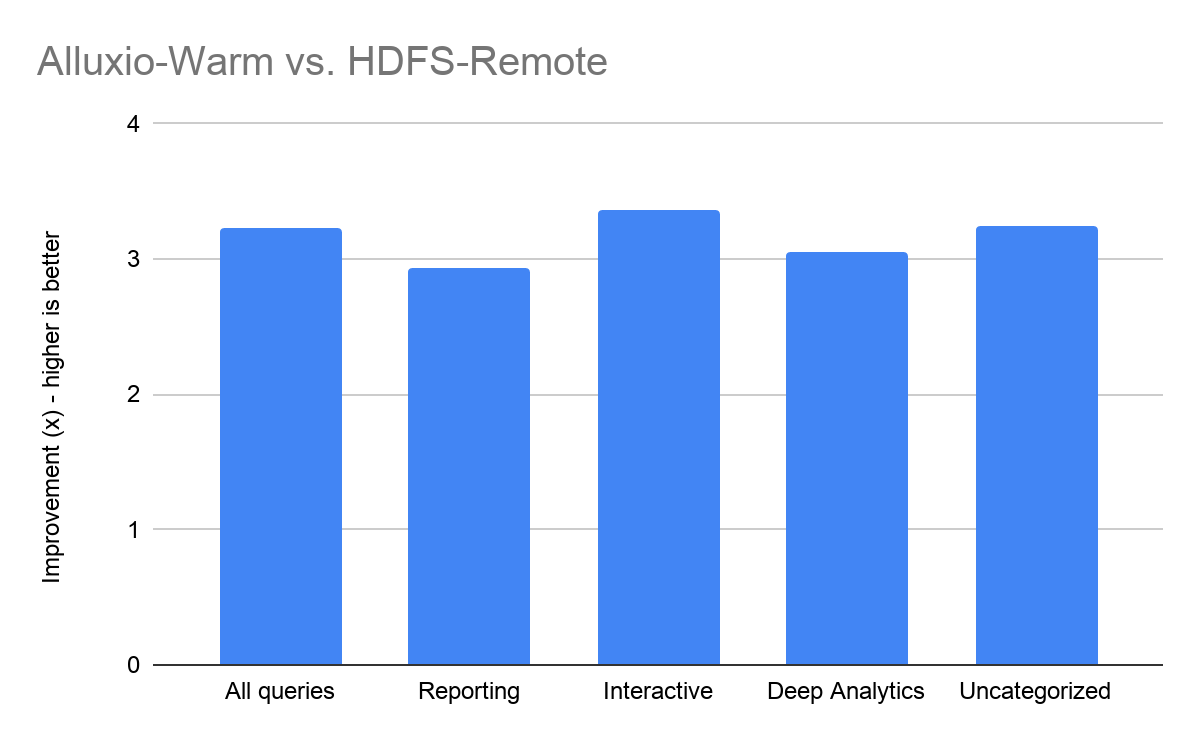
The following table summarizes the results by class. Overall the maximum improvement seen with Alluxio was for q9 (7.1x) and the minimum was for q39a (1x - no difference).
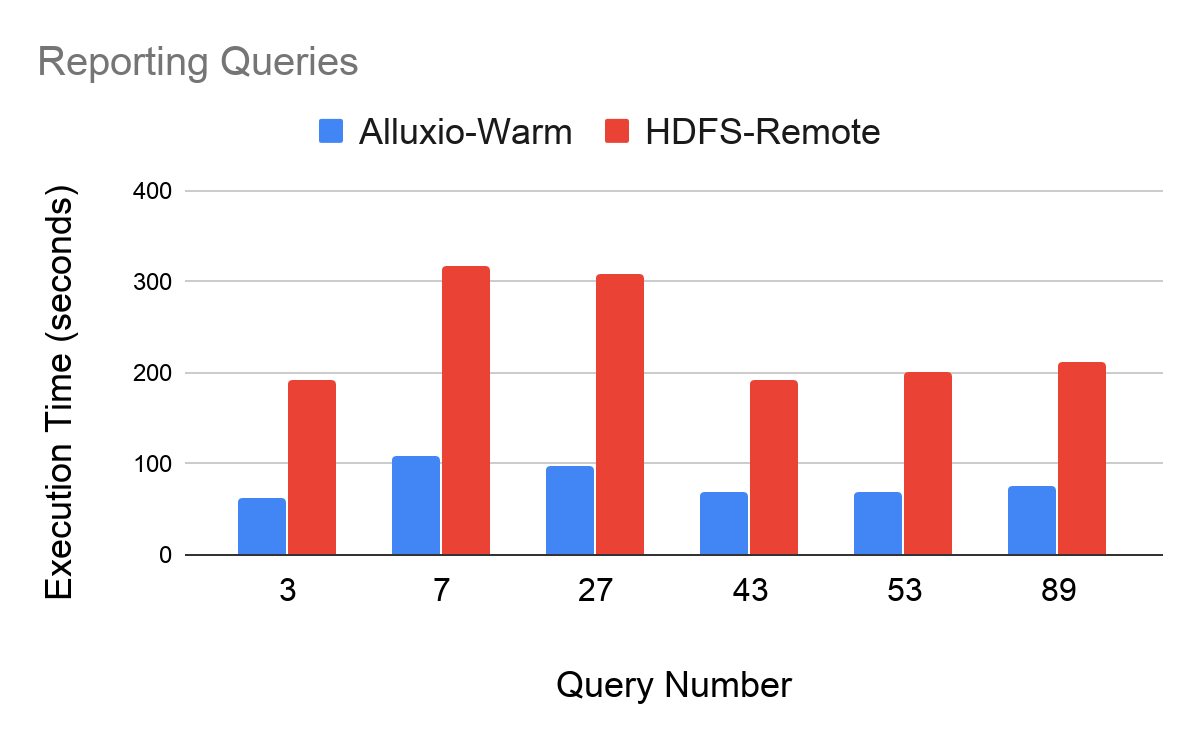
Query Class: Reporting Max Improvement: q27 (3.1x) Min Improvement: q43 (2.7x)
Query Class: Interactive Max Improvement: q73 (3.9x) Min Improvement: q98 (2.2x)
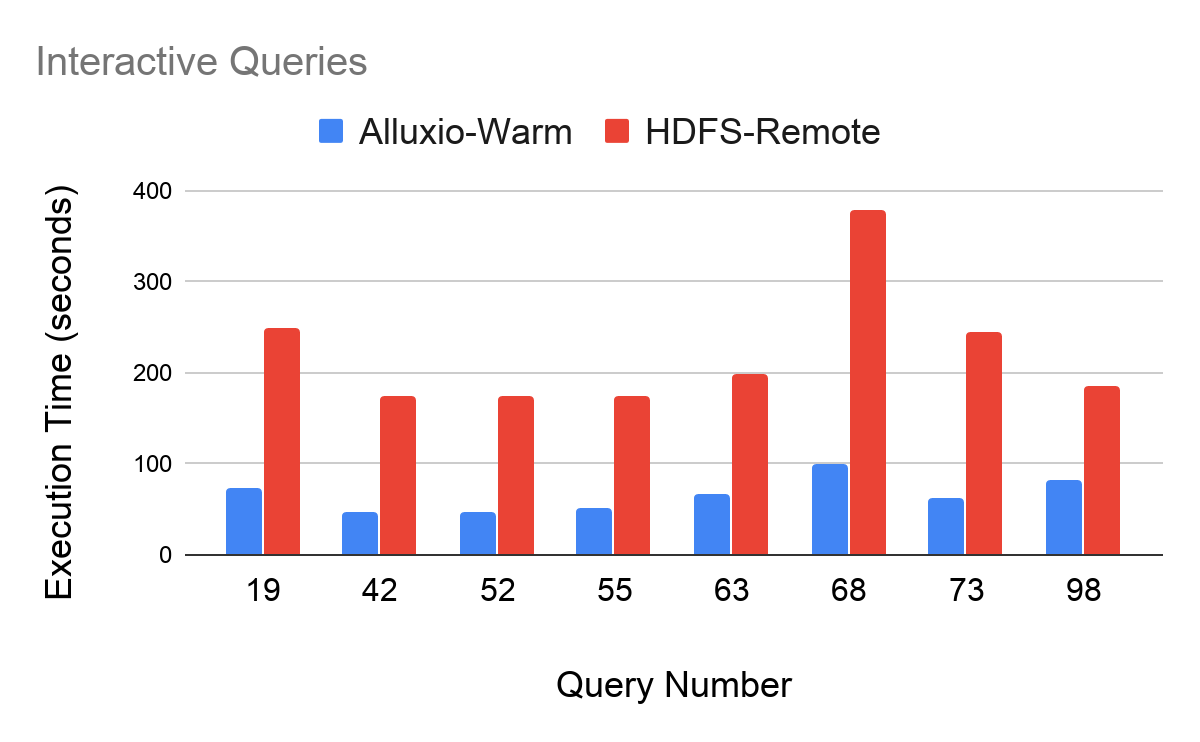
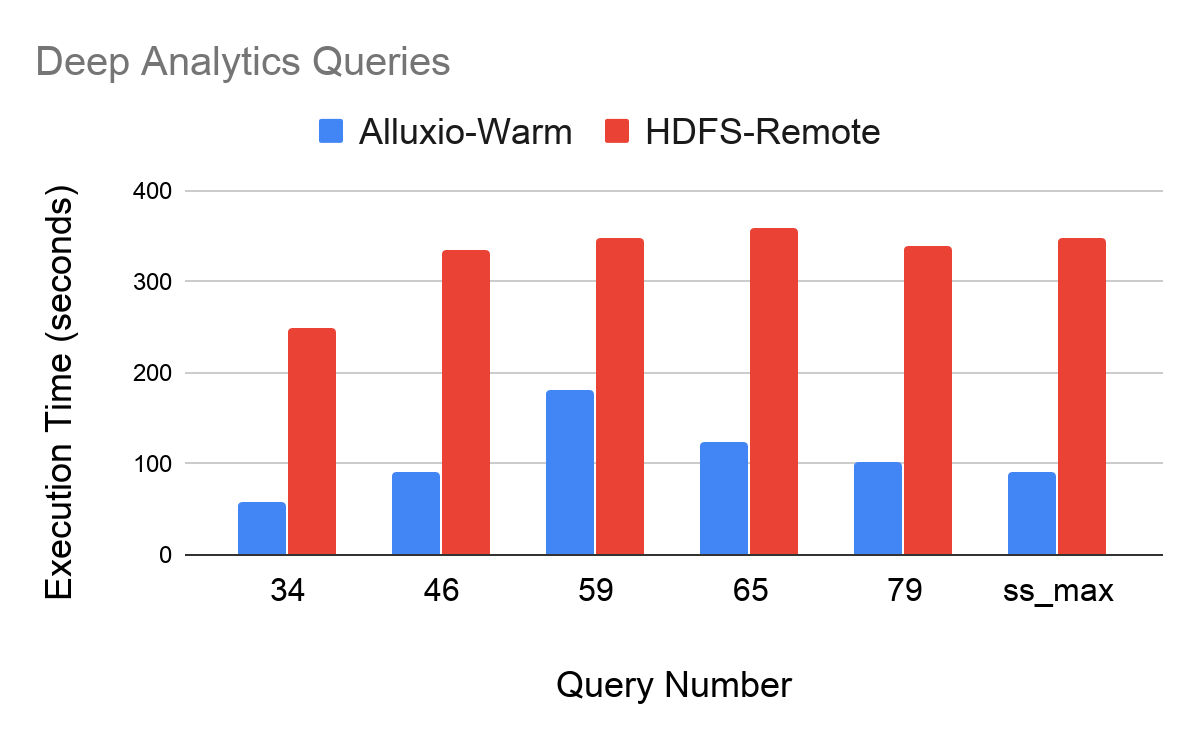
Query Class: Deep Analytics Max Improvement: q34 (4.2x) Min Improvement: q59 (1.9x)
With a 10 node compute cluster, the peak bandwidth utilization throughout running all the queries remained under 2Gbps when accessing data from the geographically separated cluster. Bandwidth was not the bottleneck with the AWS backbone network. As the utilization scales with the size of the compute cluster, a bandwidth bottleneck could be expected for larger clusters when not using Alluxio since the bandwidth available with Direct Connect may be limited.
Most of the performance gain seen with Alluxio is explained by the latency difference for both metadata and data, when cached seamlessly into the localized Alluxio cluster.
Conclusion
A hybrid cloud architecture allows cloud computing resources to be used for data analytics, even if the data resides in a completely different network. In addition to achieving significantly better performance, the execution plan outlined does not require any significant reconfiguration of the on-premise infrastructure. Since users can harness the compute power of a public cloud, this opens up more opportunities for Presto to be utilized as a scalable and performant compute framework for analytics using data stored on-premises.
An in-depth whitepaper, “Zero-Copy” Hybrid Cloud for Data Analytics - Strategy, Architecture, and Benchmark Report, was originally published by Alluxio on the Alluxio Engineering Blog on April 6, 2020. Check out the blogs for more articles about Alluxio’s engineering work and join Alluxio Open Source community on Slack for any questions you might have.