PrestoDB and Apache Hudi
Co-author: Brandon Scheller
Apache Hudi is a fast growing data lake storage system that helps organizations build and manage petabyte-scale data lakes. Hudi brings stream style processing to batch-like big data by introducing primitives such as upserts, deletes and incremental queries. These features help surface faster, fresher data on a unified serving layer. Hudi tables can be stored on the Hadoop Distributed File System (HDFS) or cloud stores and integrates well with popular query engines such as Presto, Apache Hive, Apache Spark and Apache Impala. Given Hudi pioneered a new model that moved beyond just writing files to a more managed storage layer that interops with all major query engines, there were interesting learnings on how integration points evolved.
In this blog we are going to discuss how the Presto-Hudi integration has evolved over time and also discuss upcoming file listing and query planning improvements to Presto-Hudi queries.
Apache Hudi overview
Apache Hudi (Hudi for short, here on) enables storing vast amounts of data on top of existing DFS compatible storage while also enabling stream processing in addition to typical batch-processing. This is made possible by providing two new primitives. Specifically,
- Update/Delete Records: Hudi provides support for updating/deleting records, using fine grained file/record level indexes, while providing transactional guarantees for the write operation. Queries process the last such committed snapshot, to produce results.
- Change Streams: Hudi also provides first-class support for obtaining an incremental stream of all the records that were updated/inserted/deleted in a given table, from a given point-in-time, and unlocks a new incremental-query category.
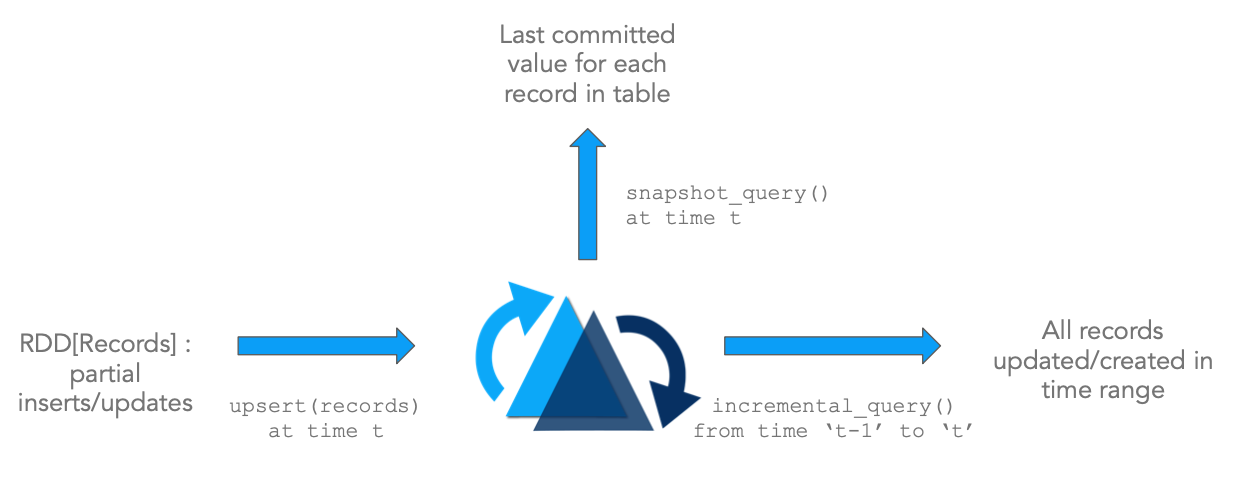 The above diagram illustrates Hudi's primitives.
The above diagram illustrates Hudi's primitives.
These primitives work closely hand-in-glove and unlock stream/incremental processing capabilities directly on top of DFS-abstractions. This is very similar to consuming events from a kafka-topic and then using a state-store to accumulate intermediate results incrementally. It has several architectural advantages.
- Increased Efficiency: Ingesting data often needs to deal with updates (resulting from database-change-capture), deletions (due to data-privacy-regulations) and enforcing unique-key-constraints (to ensure data-quality of event streams/analytics). However, due to lack of standardized support for such functionality, data engineers often resort to big batch jobs that reprocess entire day's events or reload the entire upstream database every run, leading to massive waste of computational-resources. Since Hudi supports record level updates, it brings an order of magnitude improvement to these operations, by only reprocessing changed records and rewriting only the part of the table that was updated/deleted, as opposed to rewriting entire table-partitions or even the entire table.
- Faster ETL/Derived Pipelines: A ubiquitous next step, once the data has been ingested from external sources is to build derived data pipelines using Apache Spark/Apache Hive, or any other data processing framework, to ETL the ingested data for a variety of use-cases like data-warehousing, machine-learning-feature-extraction, or even just analytics. Typically, such processes again rely on batch-processing jobs, expressed in code or SQL, that process all input data in bulk and recompute all the output results. Such data pipelines can be sped up dramatically, by querying one or more input tables using an incremental-query instead of a regular snapshot-query, resulting in only processing the incremental changes from upstream tables, and then upsert or delete on the target derived table, as depicted in the first diagram.
- Access to fresh data: It's not everyday we will find that reduced resource usage also results in improved performance, since typically we add more resources (e.g memory) to improve performance metric (e.g query latency). By fundamentally shifting away from how datasets have been traditionally managed, for what may be the first time since the dawn of the big data era, Hudi realizes this rare combination. A sweet side-effect of incrementalizing batch-processing is that the pipelines also take a much smaller amount of time to run. This puts data into hands of organizations much more quickly than has been possible with data-lakes before.
- Unified Storage: Building upon all the three benefits above, faster and lighter processing right on top of existing data-lakes mean lesser need for specialized storage or data-marts, simply for purposes of gaining access to near real-time data.
Types of Hudi tables and queries
Table Types
Hudi supports the following table types.
Copy On Write (COW): Stores data using exclusively columnar file formats (e.g parquet). Updates version & rewrites the files by performing a synchronous merge during write.
Merge On Read (MOR): Stores data using file versions with combination of columnar (e.g parquet) + row based (e.g avro) file formats. Updates are logged to delta files & later compacted to produce new versions of columnar files synchronously or asynchronously.
The following table summarizes the trade-offs between these two table types.
| Trade-off | CopyOnWrite | MergeOnRead |
|---|---|---|
| Data Latency | Higher | Lower |
| Update cost (I/O) | Higher (rewrite entire parquet) | Lower (append to delta log) |
| Parquet File Size | Smaller (high update (I/0) cost) | Larger (low update cost) |
| Write Amplification | Higher | Lower (depending on compaction strategy) |
Query types
Hudi supports the following query types.
Snapshot Queries: Queries see the latest snapshot of the table as of a given commit or compaction action. In case of merge-on-read table, it exposes near-real time data (few mins) by merging the base and delta files of the latest file version on-the-fly. For copy-on-write tables, it provides a drop-in replacement for existing parquet tables, while providing upsert/delete and other write side features.
Incremental Queries: Queries only see new data written to the table since a given commit/compaction. This effectively provides change streams to enable incremental data pipelines.
Read Optimized Queries: Queries see the latest snapshot of a table as of a given commit/compaction action. Exposes only the base/columnar files in latest file versions and guarantees the same columnar query performance compared to a non-hudi columnar table.
The following table summarizes the trade-offs between the different query types.
| Trade-off | Snapshot | Read Optimized |
|---|---|---|
| Data Latency | Lower | Higher |
| Query Latency | COW: Same as query engine on plain parquet. MOR: Higher (merge base / columnar file + row based delta / log files) | Same columnar query performance as COW Snapshot queries |
The following animations illustrate a simplified version of how inserts/updates are stored in a COW and a MOR table along with query results along the timeline. Note that X axis indicates the timeline and query results for each query type.
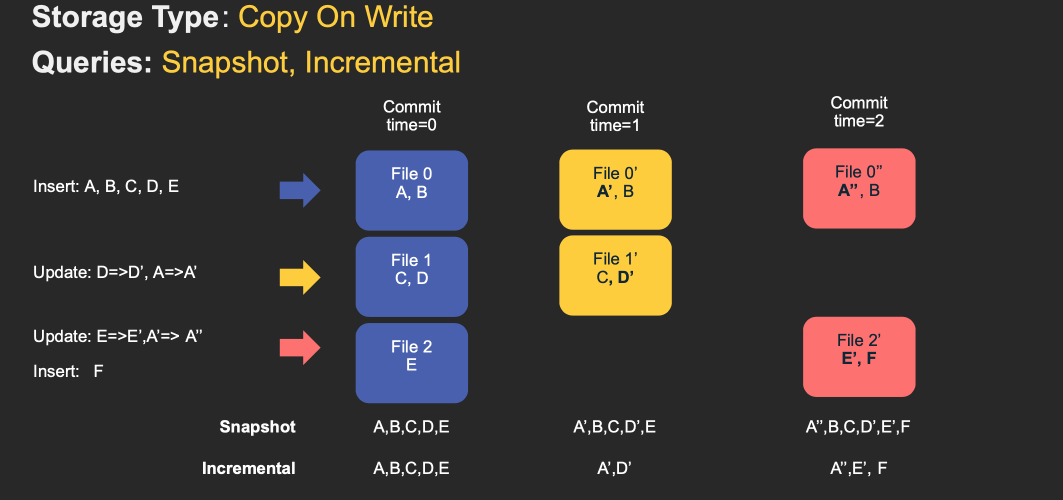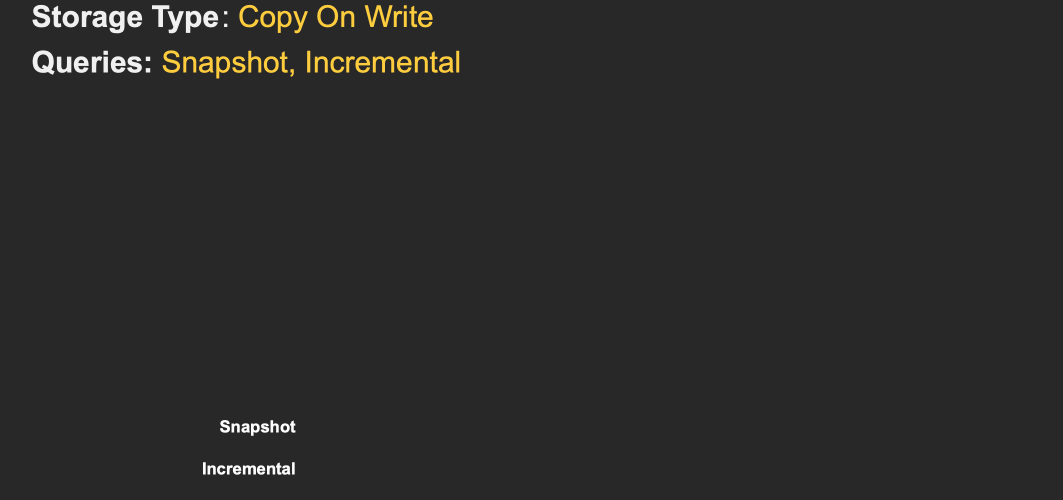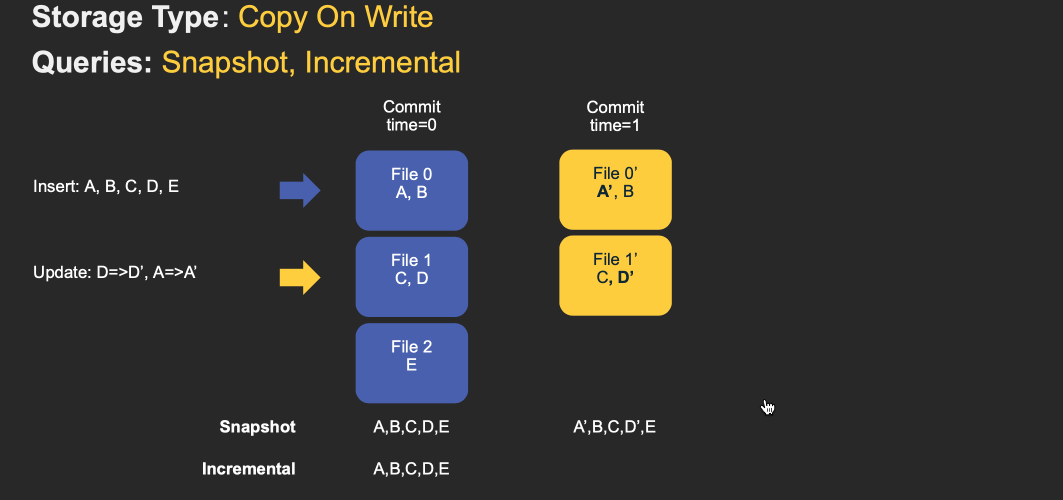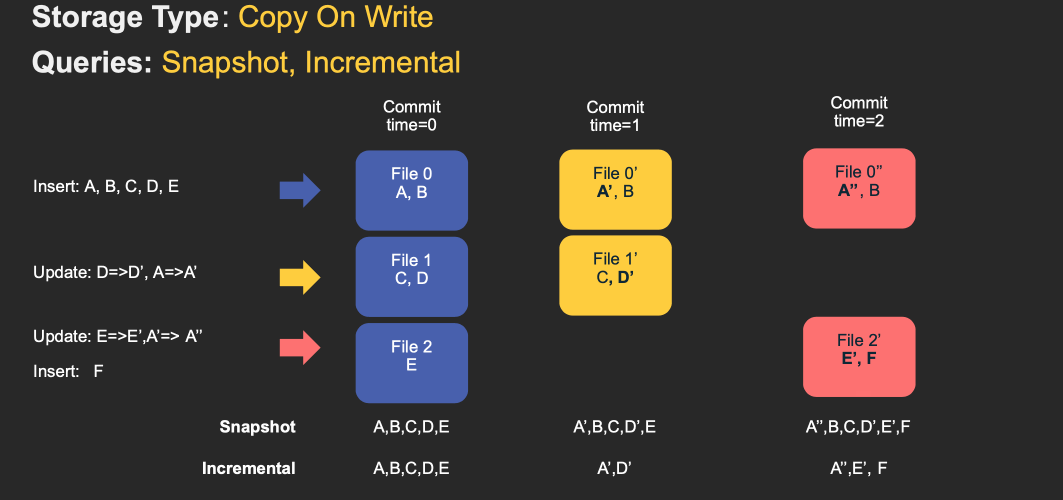
Note that the table’s commits are fully merged into the table as part of the write operation. For updates, the file containing the record is re-written with new values for all records that are changed. For inserts, the records are first packed onto the smallest file in each partition path, until it reaches the configured maximum size. Any remaining records after that, are again packed into new file id groups, again meeting the size requirements.

At a high level, MOR writer goes through the same stages as COW writer in ingesting data. The updates are appended to the latest log (delta) file belonging to the latest file version without merging. For inserts, Hudi supports 2 modes:
- Inserts to log files - This is done for tables that have an indexable log files (for e.g. hbase index or the upcoming record level index)
- Inserts to parquet files - This is done for tables that do not have indexable log files, for example bloom index
At a later time, the log files are merged with the base parquet file by compaction action in the timeline. This table type is the most versatile, highly advanced and offers much flexibility for writing (ability to specify different compaction policies, absorb bursty write traffic etc) and querying (e.g: tradeoff data freshness and query performance). At the same time, it can involve a learning curve for mastering it operationally.
Early Presto integration
Hudi was designed in mid to late 2016. At that time, we were looking to integrate with query engines in the Hadoop ecosystem. To achieve this in Presto, we introduced a custom annotation - @UseFileSplitsFromInputFormat, as suggested by the community. Any Hive registered table if it has this annotation would fetch splits by invoking the corresponding inputformat’s getSplits() method instead of Presto Hive’s native split loading logic. For Hudi tables queried via Presto this would be a simple call to HoodieParquetInputFormat.getSplits(). This was a straightforward and simple integration. All one had to do was drop in the corresponding Hudi jars under <presto_install>/plugin/hive-hadoop2/ directory. This supported querying COW Hudi tables and read optimized querying of MOR Hudi tables (only fetch data from compacted base parquet files). At Uber, this simple integration already supported over 100,000 Presto queries per day from 100s of petabytes of data (raw data and modeled tables) sitting in HDFS ingested using Hudi.
Moving away from InputFormat.getSplits()
While invoking inputformat.getSplits() was a simple integration, we noticed that this could cause a lot of RPC calls to namenode. There were several disadvantages to the previous approach.
- The
InputSplits returned from Hudi are not enough. Presto needs to know the file status and block locations for each of theInputSplitreturned. So this added 2 extra RPCs to the namenode for every split times the number of partitions loaded. Occasionally, backpressure can be observed if the namenode is under a lot of pressure. - Furthermore, for every partition loaded (per
loadPartition()call) in Presto split calculation,HoodieParquetInputFormat.getSplits()would be invoked. That caused redundant Hoodie table metadata listing, which otherwise can be reused for all partitions belonging to a table scanned from a query.
This led us to rethink the Presto-Hudi integration. At Uber, we changed this implementation by adding a compile time dependency on Hudi and instantiated the HoodieTableMetadata once in the BackgroundHiveSplitLoader constructor. We then leveraged Hudi Library APIs to filter the partition files instead of calling HoodieParquetInputFormat.getSplits(). This gave a significant reduction in the number of namenode calls in this path.
Towards generalizing this approach and making it available for the Presto-Hudi community, we added a new API in Presto’s DirectoryLister interface that would take in a PathFilter object. For Hudi tables, we supplied this PathFilter object - HoodieROTablePathFilter, which would take care of filtering the files that Presto lists for querying Hudi tables and achieve the same results as Uber’s internal solution.
This change is available since the 0.233 version of Presto and depends on the 0.5.1-incubating Hudi version. Since Hudi is now a compile time dependency it is no longer necessary to provide Hudi jar files in the plugin directory.
Presto support for querying MOR tables in Hudi
We are starting to see more interest among the community to add support for snapshot querying of Hudi MOR tables from Presto. So far, from Presto, only read optimized queries (pure columnar data) are supported on Hudi tables. With this PR in progress - https://github.com/prestodb/presto/pull/14795 we are excited that snapshot querying (aka real time querying) of Hudi MOR tables will be available soon. This would make fresher data available for querying by merging base file (Parquet data) and log files (Avro data) at read time.
In Hive, this can be made available by introducing a separate InputFormat class that provides ways to deal with splits and a new RecordReader class that can scan the split to fetch records. For Hive to query MOR Hudi tables there is already such classes available in Hudi:
InputFormat-org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormatInputSplit-org.apache.hudi.hadoop.realtime.HoodieRealtimeFileSplitRecordReader-org.apache.hudi.hadoop.realtime.HoodieRealtimeRecordReaderSupporting this in Presto involves understanding how Presto fetches records from Hive tables and making necessary changes in that layer. Because Presto uses its nativeParquetPageSourcerather than the record reader from the input format, Presto would only show the base parquet files, and not show the real time upserts from Hudi's log files which are avro data (essentially the same as a normal read-optimized Hudi query).
To allow Hudi real time queries to work, we identified and made the following separate necessary changes:
Add extra metadata field to serializable
HiveSplitto store Hudi split information. Presto-hive converts its splits into the serializableHiveSplitto pass around. Because it expects standard splits, it will lose the context of any extra information contained in complex splits extended fromFileSplit. Our first thought was to simply add the entire complex split as an extra field ofHiveSplit. This didn't work however as the complex splits were not serializable and this would also duplicate the base split data.Instead we added a
CustomSplitConverterinterface. This accepts a custom split and returns an easily serializable String->String map containing the extra data from the custom split. To complement this, we also added this Map as an additional field to Presto'sHiveSplit. We created theHudiRealtimeSplitConverterto implementCustomSplitConverterinterface for Hudi real time queries.Recreate Hudi split from
HiveSplit's extra metadata. Now that we have the full information of the custom split contained inHiveSplit, we need to identify and recreate theHoodieRealtimeFileSplitjust before reading the split. The sameCustomSplitConverterinterface has another method that takes a normalFileSplit+ extra split information map and returns the actual complex FileSplit, in this case theHudiRealtimeFileSplit. This leads to our last and final change.Use
HoodieRealtimeRecordReaderfromHoodieParquetRealtimeInputFormatto read recreatedHoodieRealtimeFileSplit. Presto needs to use the new record reader to properly handle the extra information in theHudiRealtimeFileSplit. To do this we introduced another annotation@UseRecordReaderFromInputFormatsimilar to the first annotation. This signals Presto to use the Hive record cursor (which uses the record reader from the input format) instead of the page source. The Hive record cursor sees the recreated custom split and sets additional information/configs based on the custom split.
With these changes, Presto users should be able to access more real time data on Hudi MOR tables.
What’s next?
Following are some interesting efforts (we call them RFCs) we are looking into that may need support in Presto.
RFC-12: Bootstrapping Hudi tables efficiently
Apache Hudi maintains per record metadata that enables us to provide record level upserts, unique key semantics and database-like change streams. However, this meant that, to take advantage of Hudi’s upsert and incremental processing support, users would need to rewrite their whole dataset to make it an Apache Hudi table. This RFC provides a mechanism to efficiently migrate their datasets without the need to rewrite the entire dataset, while also providing the full capabilities of Hudi.
This will be achieved by having mechanisms to refer to the external data files (from the source table) from within the new bootstrapped Hudi table. With the possibility of data residing in an external location (bootstrapped data) or under Hudi table’s basepath (recent data), FileSplits would require to store more metadata on these. This work would also leverage and build upon the Presto MOR query support we are adding currently.
Support Incremental and point in time time-travel queries on Hudi tables
Incremental queries allow us to extract change logs from a source Hudi table. Point in time queries allows for getting the state of a Hudi table between time T1 and T2. These are supported in Hive and Spark already. We are looking into supporting this feature in Presto as well.
In Hive incremental queries are supported by setting few configs in JobConf like for example - query mode to INCREMENTAL, starting commit time and max number of commits to consume. In Spark, there is a specific implementation to support incremental querying - IncrementalRelation. To support this in Presto, we need a way to identify the incremental query. Given Presto does not pass arbitrary session configs to the hadoop configuration object, an initial idea is to register the same table in the metastore as an incremental table. And then use query predicates to get other details such as starting commit time, max commits etc.
RFC-15: Query planning and listing improvements
Hudi write client and Hudi queries need to perform listStatus operation on the file system to get a current view of the file system. While at Uber, the HDFS infrastructure was heavily optimized for listing, this can be an expensive op for large datasets containing thousands of partitions and each partition having thousands of files on cloud/object storage. The above RFC work aims at eliminating list operation and providing better query performance and faster lookups, by simply incrementally compacting Hudi’s timeline metadata into a snapshot of a table’s state at that instant.
The solutions here aim at
- Ways for storing and maintaining metadata of the latest list of files.
- Maintaining stats on all columns of a table to aid effective pruning of files before scanning. This can be leveraged in the query planning phase of the engine.
Towards this, Presto would need some changes too. We are actively exploring ways to leverage such metadata in the query planning phase. This would be a significant addition to Presto-Hudi integration and would push the query latencies further down.
Upsert is a popular write operation on Hudi tables that relies on indexing to tag incoming records as upserts. HoodieIndex provides a mapping of a record id to a file id in both a partitioned or a non-partitioned dataset, with implementations backed by BloomFilters/ Key ranges (for temporal data), and also Apache HBase (for random updates). Many users find Apache HBase (or any such key-value store backed index) expensive and adding to operational overhead. This effort tries to come up with a new index format for indexing at record level, natively within Hudi. Hudi would store and maintain the record level index (backed by pluggable storage implementations such as HFile, RocksDB). This would be used by both the writer (ingestion) and readers (ingestion/queries) and would significantly improve upsert performance over join based approaches or even bloom index for random update workloads. This is another area where query engines could leverage this information when pruning files before listing them. We are also looking at a way to leverage this metadata from Presto when querying.
Moving forward
Query engines like Presto are the gateways for users to reap the strength of Hudi. With an ever growing community and active development roadmap there are many interesting projects in Hudi. As Hudi invests heavily into the projects above, there is only greater need to deeply integrate with systems like Presto. Towards that, we look forward to collaborating with the Presto community. We welcome suggestions, feedback and encourage you to make contributions and connect with us here.