Building a high-performance platform on AWS to support real-time gaming services using Presto and Alluxio
Authors: Teng Wang, Du Li, Yu Jin and Sundeep Narravula
Electronic Arts (EA) is a leading company in the gaming industry, providing dozens of games to serve billions of users worldwide each year. Making near real-time decisions for EA’s online services is critical for our business. This blog describes a data platform on AWS based on Presto and Alluxio to support online services with instantaneous response within the gaming industry.

The EA Data & AI Department builds hundreds of platforms to manage petabytes of data generated by games and users everyday. These platforms consist of a wide range of data analytics, from real-time data ingestion to ETL pipelines. Formatted data produced by our department is widely adopted by executives, producers, product managers, game engineers, and designers for marketing and monetization, game design, customer engagement, player retention, and end-user experience.
Use Cases
Near real-time information for EA’s online services is critical for making business decisions, such as campaigns and troubleshooting. These services include, but are not limited to, real-time data visualization, dashboarding, and conversational analytics. Our team is actively seeking a framework that can support these use cases.
At EA, we have adopted numerous data visualization tools, such as Tableau and Dundas, to support data insight analytics. These tools are usually connected with multiple data sources, such as MySQL DB, AWS S3, or HDFS. Users can load data from multiple endpoints simultaneously to run computationally heavy algorithms. One severe performance bottleneck is loading data as it is I/O heavy. This could be exacerbated more if the same data needs to be loaded multiple times. Thus we need a solution to reduce this data retrieving overhead by caching the data locally.
Dashboarding is another common use case, used to keep tracking user engagements, customer satisfaction, or system status in real-time. In these cases, the data volume is usually on the order of gigabytes, but frequent refreshes require instantaneous processing. Currently, we use commercial databases such as Redshift to serve time-sensitive data, and we are seeking an alternative to slash costs without losing performance.
We recently developed a reporting chatbot to provide immediate game related insights, such as live user satisfaction and real-time profit analysis. The backend of this system runs Presto with petabytes of data stored on S3. This chatbot converts user's questions into ANSI SQL and runs these queries on a Presto cluster. The queries usually conduct complex computations, such as prediction and merging after searching across datasets. We are eager to find a solution that compliments our S3 based datasets to improve the performance without introducing extra cost.
Architecture
To serve these different use cases with near-realtime requirements, we built and evaluated Presto as our data query platform with data in S3, and the working set cached in Alluxio. In this blog we compare a mock of the aforementioned production setup of Presto on S3 against a similar stack with Alluxio. The architecture is shown below:
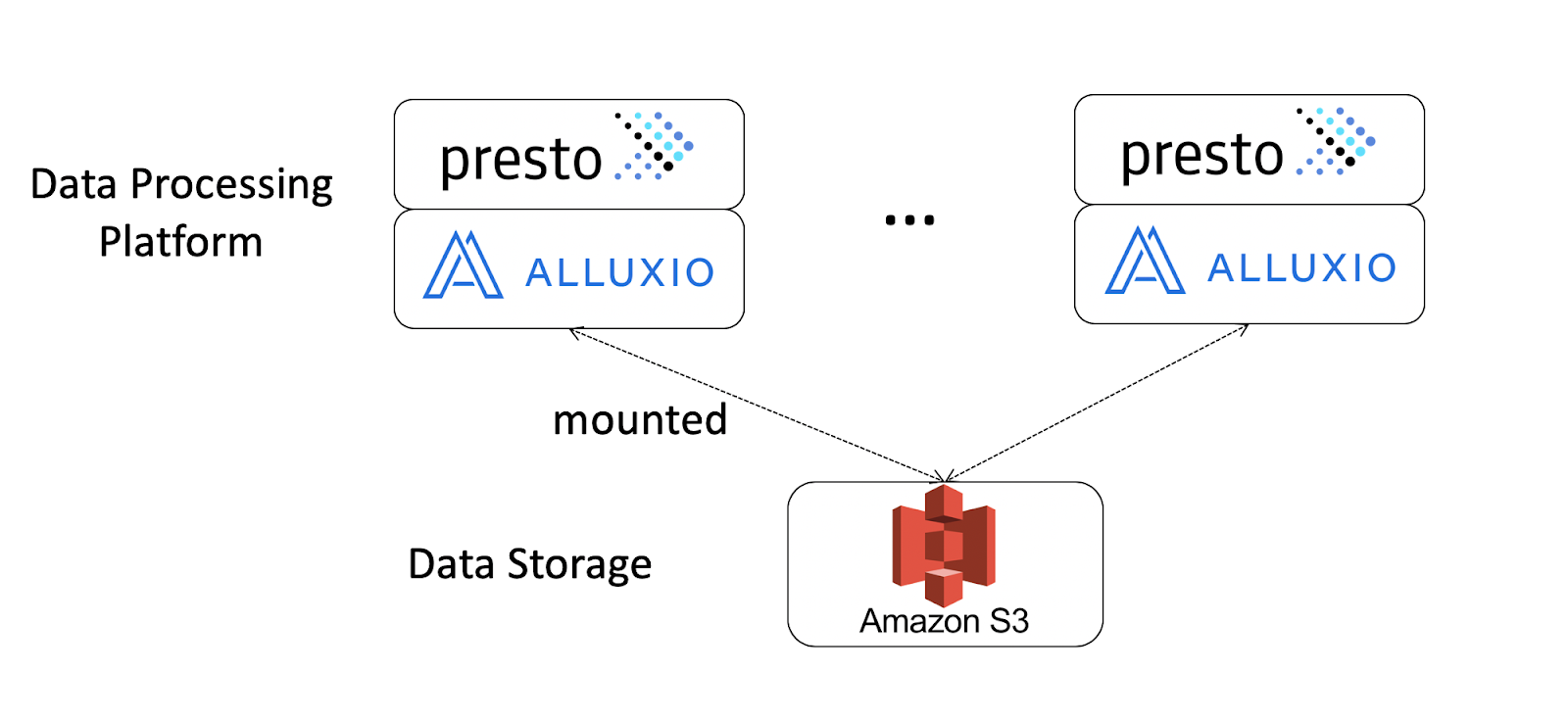
Here are some more details about our setup:
- Each instance launched Presto and Alluxio, co-locating the two services.
- For hardware, we used three h1.8xlarge AWS instances, each with 8TB ephemeral disks mounted for use by Alluxio to cache data local to Presto.
- S3 was mounted to Alluxio as the underlying persisting file system.
- Two catalogs were configured for Presto; one connected to our existing Hive metastore, referencing the benchmark datasets externally stored on S3, and the other connected to a separate - Hive metastore with the benchmark tables created in Alluxio.
- We used the same datasets on S3 for performance comparison and pre-loaded the data into Alluxio with
alluxio fs distributedLoad /testDB - To optimize the query performance when processing large amounts of small files, we enabled metadata caching in
alluxio-site.propertiesto tune the performance
alluxio.user.metadata.cache.enabled=true
alluxio.user.metadata.cache.max.size=100000
alluxio.user.metadata.cache.expiration.time=10min
Benchmark Result
Four independent benchmarks representing a wide range of different workloads were selected. The baseline is the performance when Presto was querying S3 directly.
Benchmark 1 is our internal synthesis snapshots of player in-game events, representing I/O heavy use cases. Three datasets were tested with a total size of 1GB, 10GB, and 100GB and files in ORC format. Each dataset is created with the same DDL, containing 49 cols, 40 varchar, 5 booleans, and 4 maps. The benchmark queries select all columns with one varchar field filter condition.
Result: With caching data in Alluxio, Presto performs 2x to 7x faster compared to the baseline when querying S3 directly.
Benchmark 2 simulates data visualization with game metadata and user engagement records.
which is a typical query that stresses both CPU and I/O.
With two commonly used datasets and queries frequently used in Tableau and Dundas respectively,
the queries select all columns with a date filtering condition, followed by GROUP BY and ORDER BY of the date.
In this test, we intentionally disabled Alluxio metadata caching which already shows significant improvement, to understand how data caching helps here.
Result: Without metadata caching, Presto with Alluxio is 2.75x faster than S3 with the Dundas dataset and 5.1x faster with the Tableau dataset.
Benchmark 3 simulates our dashboarding use case using a dataset with a large number of small files. The datasets are batches of 2MB files, totalling to 50, 500, and 5000 files. The query used is a select query aggregating the number of entries for each date.
Result: Alluxio with metadata caching is 1.2x to 5.9x faster than S3. Without metadata caching, Alluxio is only 1x to 1.35x faster. Enabling metadata caching significantly reduces the execution time by memorizing metadata, recognizing hot data and increasing replicas.
Benchmark 4 simulates the conversational bot. The dataset used was a snapshot of daily game performance. The query contains multiple stages of calculation to simulate a CPU intensive query. It converts an integer field into HyperLogLog, merges it, and selects the cardinality. The results are filtered by an integer and varchar field.
Result: Alluxio without metadata caching shortens the timespan from 85.2 seconds to 3 seconds, which improves the performance as much as 27x.
Conclusion
This blog explores an innovative platform with Presto as the computing engine and Alluxio as a data orchestration layer between Presto and S3 storage, to support online services with instantaneous response within the gaming industry. We evaluated this platform with real industrial examples of data visualization, dashboarding, and a conversational chatbot. Our preliminary results show that Presto with Alluxio outperforms S3 significantly in all cases. In particular, Alluxio with metadata caching shows up to 5.9x performance gain when handling large numbers of small files. Alluxio enables the separation of storage and compute by managing the allocated ephemeral disks to cache data from S3 local to Presto. Advanced cache management with an asymmetric number of replicas for hot vs. cold data accounts for performance gains in each scenario we tested.