Presto Enables Internal Log Data Analysis at Drift
I’m a Senior Software Engineer in the data group at Drift, a conversational marketing platform that is used for qualifying leads faster, automatically booking meetings and connecting customers to the right business solutions more efficiently. I’ve used Presto quite a bit throughout my career, and I want to first give readers a quick overview of how Presto has enabled my team at Drift to quickly and cost-effectively analyze distributed logs at scale. Then I will share how we used and benefited from Presto at Vistaprint, where I worked previously.
## How we use Presto at DriftTo provide data engineers in my group with the ability to mine log files, we use Amazon Athena which has Presto as its distributed SQL query engine for running analytic queries against data of any size.
We also use AWS Glue, an ETL service that makes it easy to categorize data, clean it, and move it between different data stores and data streams. Glue basically provides a unified metadata repository across a variety of data sources and formats, and it integrates easily with Athena.
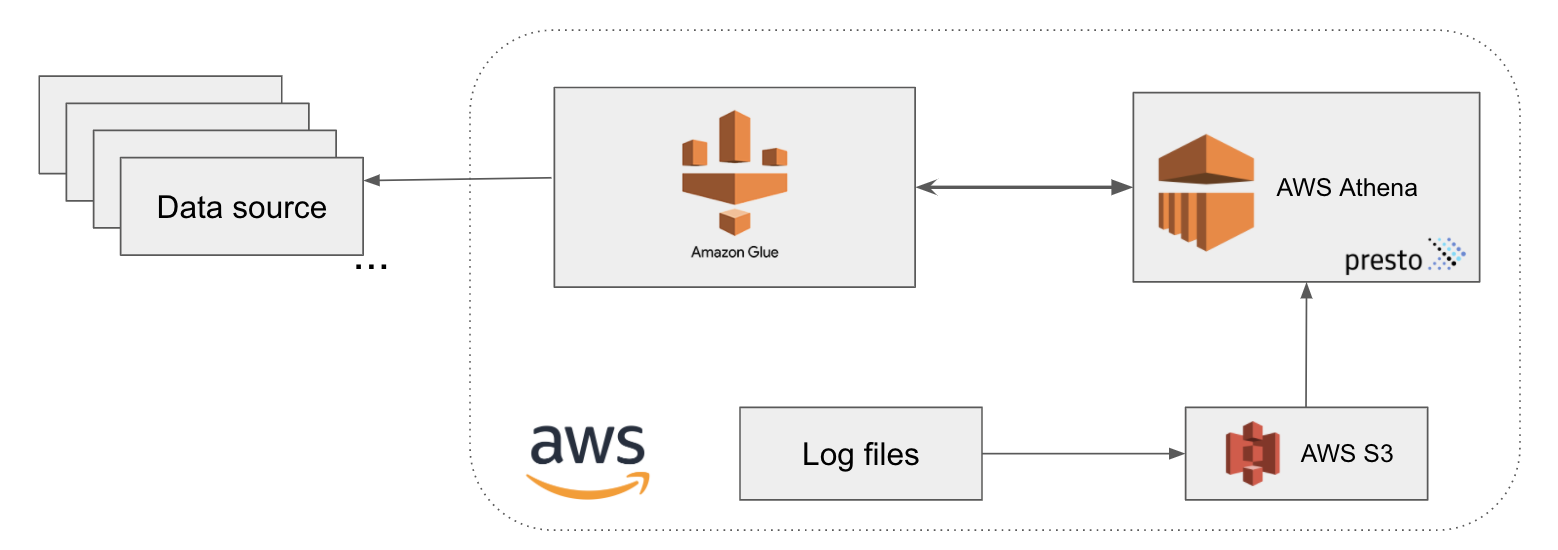
Specifically, Presto plays a key role in enabling internal analysis here at Drift. We use Presto to query both semi-structured and freeform log data such as JSON messages. With Presto, data engineers can easily drop the data into Amazon S3 without needing to perform too much data cleaning, so that Athena can read the data easily. We use that data to generate graphs that show how many log reports we’re running, or how many bad instances per hour are occurring.
Advantages of Presto
One of the main advantages of Presto in this case is that my engineering team can get to the data quickly and start querying the data immediately.
The data in Presto is completely cloud-based; it basically functions as an on-demand service query search. If the engineers need to run a massive load of data, it will automatically spin as many nodes as needed.
Business users at Drift could use Presto by querying Salesforce data using Looker, our BI and analytics platform. They would be able to easily process petabytes of data to find answers to their questions, such as how many sales opportunities were created, how many accounts they have, and the progression of the sales pipeline from qualified lead to a closed sale. The main data warehouse at Drift is Snowflake. The data loading does take a lot of development time, as it would require a lot of “scaffolding work” in order to run it. With Presto, I can drop the data in and parse it immediately.
How we used Presto at Vistaprint
I also had the opportunity to use Presto earlier in my career, while working at Vistaprint, an ecommerce platform that combined in-house software and production technology to mass-customize personalized products.
At Vistaprint, Presto was used for flow log reporting to read order data. Every five minutes, we would do a count in AWS Athena to look at orders coming through the system. If it showed that no orders came through in a 15-minute timeframe, I would get an automatic alert via Slack or text, and I would know that there was a problem that needed human intervention. Presto provided quick visibility into the logs so that we could act fast. When our Kafka ingestion cluster went down, the Lambda code that I wrote triggered a Slack alert so we could respond quickly.
The advantages of using Presto at Vistaprint
In the case with Vistaprint, Presto’s ability to efficiently and quickly query large amounts of data from multiple sources was critical. I also appreciated how easy it was to add AWS Athena/Presto to our existing system. I didn’t need to worry about node provisioning, cluster setup, Presto configuration, or cluster tuning.
Conclusion
Presto is designed and tuned for real-world workloads, and I can query data where it is stored without needing to move it into a separate analytics system. This is a huge resource and cost saver. I’m looking forward to seeing how Presto evolves over the next few years, and I’m excited to continue to use it for interactive analytic queries.