Using OptimizedTypedSet to Improve Map and Array Functions

Function evaluation is a big part of projection CPU cost. Recently we optimized a set of functions that use TypedSet, e.g. map_concat, array_union, array_intersect, and array_except. By introducing a new OptimizedTypeSet, the above functions saw improvements in several dimensions:
- Up to 80% reduction in wall time and CPU time in JMH benchmarks
- Reserved memory reduced by 5%
- Allocation rate reduced by 80%
Furthermore, OptimizedTypeSet resolves the long standing issue of throwing EXCEEDED_FUNCTION_MEMORY_LIMIT for large incoming blocks: "The input to function_name is too large. More than 4MB of memory is needed to hold the intermediate hash set.”
The OptimizedTypeSet and improvements to the above mentioned functions are merged to master, and will be available from Presto 0.244.
In this post we will look at the methods used in this improvement.
Avoid Using Internal BlockBuilder
TypedSet has an internal BlockBuilder and appends each Block position being added to it, as well as an external BlockBuilder to construct the results. Block building using BlockBuilder is very costly and inefficient, especially when memory growth is not handled properly. The BlockBuilder was needed to keep track of the elements being added, so that it can:
- Resolve hash table probing collision
- Rehash
However, BlockBuilder is not necessary for either of these issues. In all use cases, whole blocks (instead of several positions of a block) are added to the TypedSet, and the problem of resolving collisions can be resolved by keeping track of the blocks being added. Rehashing is not needed in most cases because we can calculate the maximum number of entries before creating the TypedSet.
In the new design, we provided methods that add a whole Block with different set operations:
- union
- intersect
- except
These methods take in a Block and remember the selected positions. The operations can be applied on the same set multiple times, i.e. you can union two Block A and B, then intersect with Block C, then minus(except) Block D. This way the internal operations on the Block elements can be streamlined to more efficient loops. The memory consumption and allocation were also reduced because now we only need to remember the selected positions instead of building a whole new Block internally.
Avoid Recomputing Hash Positions
Calculating hash positions took over 60% of original function costs. For some operations like set intersection, the previous implementation requires creating multiple TypedSets and calculating the hash position multiple times. For example, the array_intersect function calculates the distinct common elements from two incoming Blocks, one from the right side and the other one from the left side. It builds a TypedSet R which contains a hash table R for the right side Block first. When inserting a new element X from the left side Block, it first checks if hash table R contains the element. If not, the new element will be added to the other TypedSet L, which has another hash table L and represents the final results.
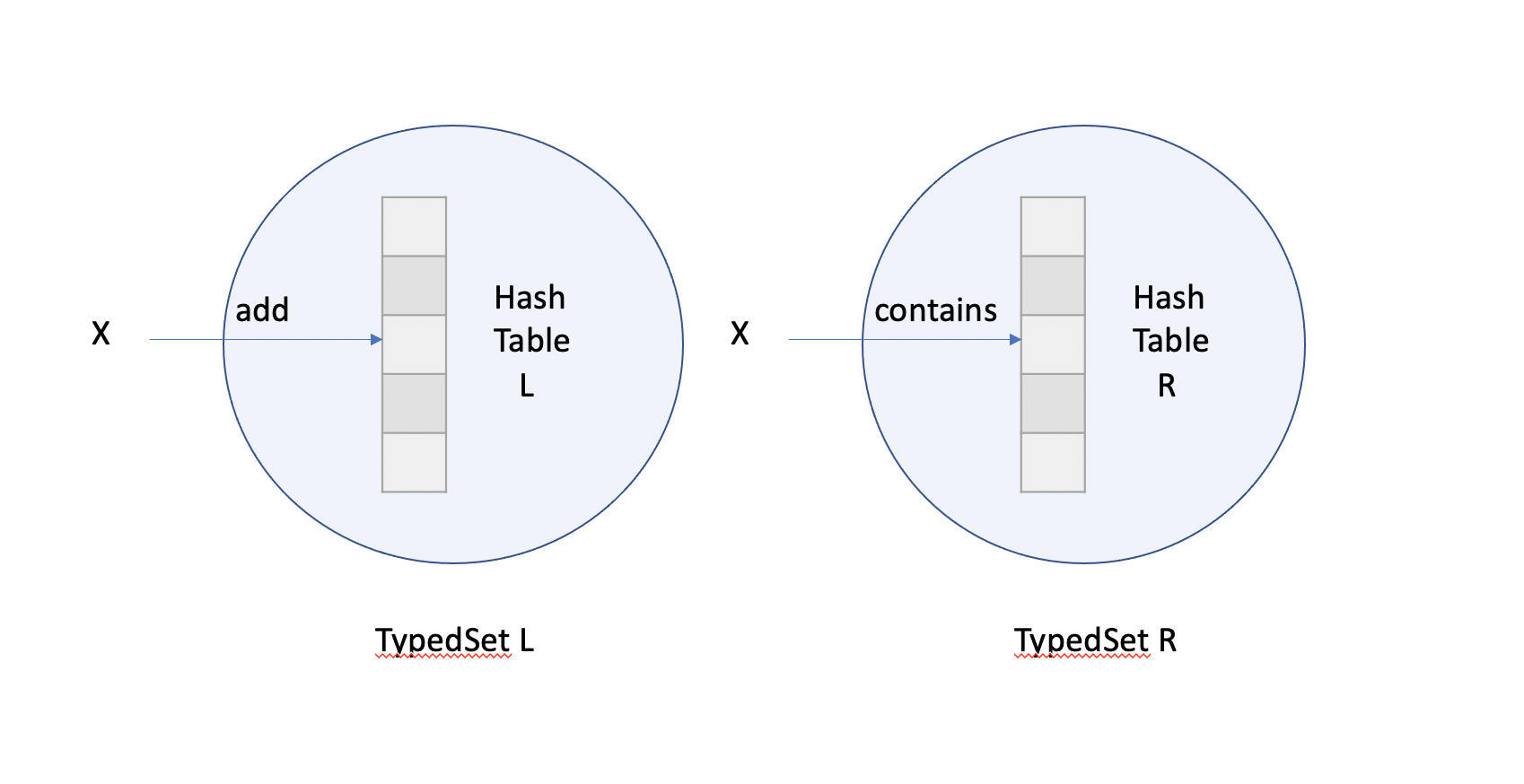
As shown in the above picture, the contains and add operation would both calculate the hash positions for hash table R and L respectively. This hash position indicates the starting position of the linear probing for both hash tables. But actually the hashPosition calculated in hash table R can be reused by hash table L if the hash table sizes and hash functions are the same.
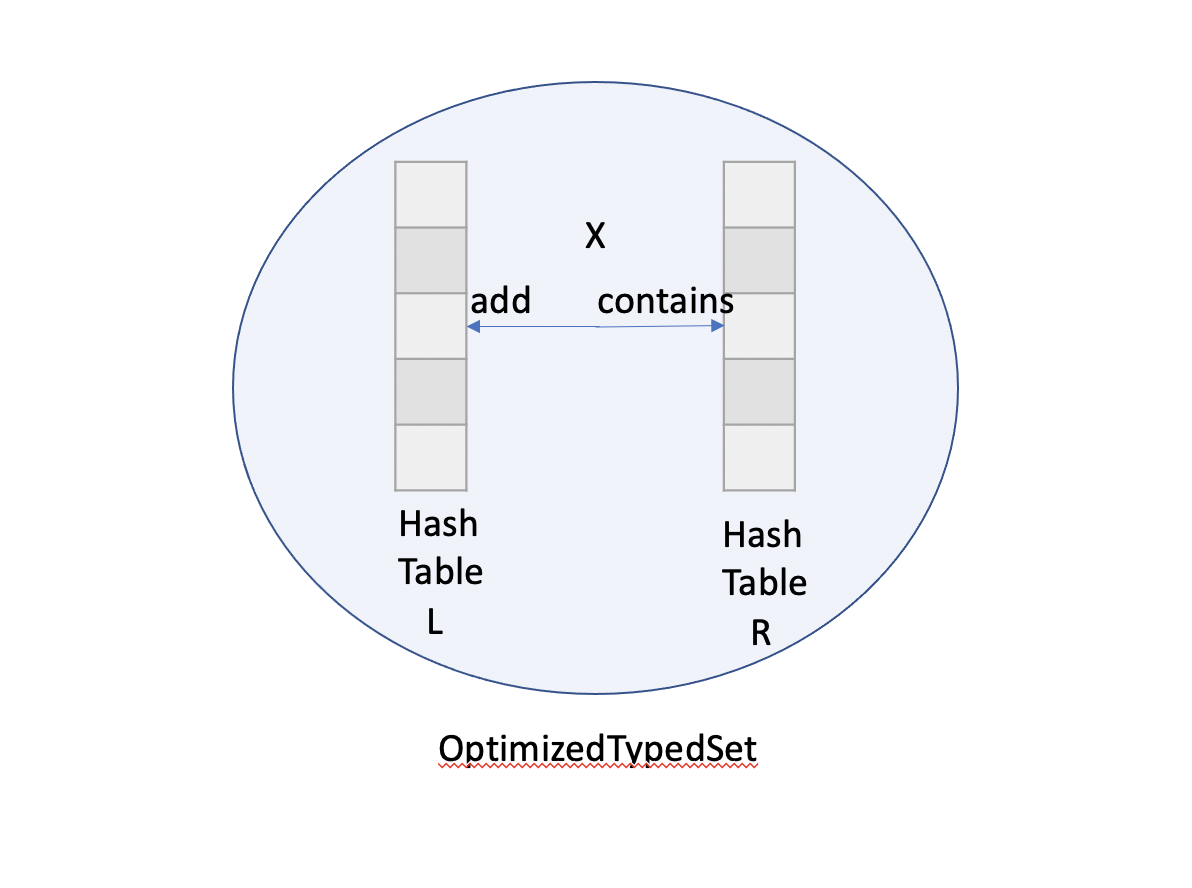
In the new OptimizedTypedSet, the first step is the same as the original implementation, in which the right side Block is added to the set first, and hash table R is constructed. Intersecting the set with the left side Block was done by creating a new hash table L of the same size (size precalculated) internally: it checks if the new elements are contained in hash table R, and if not, add them to hash table L. Unlike the original implementation, the contains and add operation share the same hash position calculation. When the new hash table L is constructed, the hash table R will be discarded.
Next Steps
The goal of the above PR was to demonstrate the benefit using the OptimizedTypedSet on 4 functions. There are a few other usages, e.g. MultimapAggregationFunction, MapFromEntriesFunction, etc. After we change them to use the new OptimizedTypedSet, the legacy TypedSet implementation can be removed.
Further reading
For more information please refer to the PR#15362.