RaptorX: Building a 10X Faster Presto

Facebook: Abhinav Sharma, Amit Dutta, Baldeep Hira, Biswapesh Chattopadhyay, James Sun, Jialiang Tan, Ke Wang, Lin Liu, Naveen Cherukuri, Nikhil Collooru, Peter Na, Prashant Nema, Rohit Jain, Saksham Sachdev, Sergey Pershin, Shixuan Fan, Varun Gajjala
Alluxio: Bin Fan, Calvin Jia, Haoyuan Li
Twitter: Zhenxiao Luo
Pinterest: Lu Niu
RaptorX is an internal project name aiming to boost query latency significantly beyond what vanilla Presto is capable of. This blog post introduces the hierarchical cache work, which is the key building block for RaptorX. With the support of the cache, we are able to boost query performance by 10X. This new architecture can beat performance oriented connectors like Raptor with the added benefit of continuing to work with disaggregated storage.
Problems with Disaggregated Storage
Disaggregated storage is the industry wide trend towards scaling storage and compute independently. It helps cloud providers reduce costs. Presto by nature supports such architecture. Data can be streamed from remote storage nodes outside of Presto servers.
However, storage-compute disaggregation also provides new challenges for query latency as scanning huge amounts of data over the wire is going to be IO bound when the network is saturated. Moreover, the metadata paths will also go through the wire to retrieve the location of the data; a few roundtrips of metadata RPCs can easily bump up the latency to more than a second. The following figure shows the IO paths for Hive connectors in orange color, each of which could be a bottleneck on query performance.
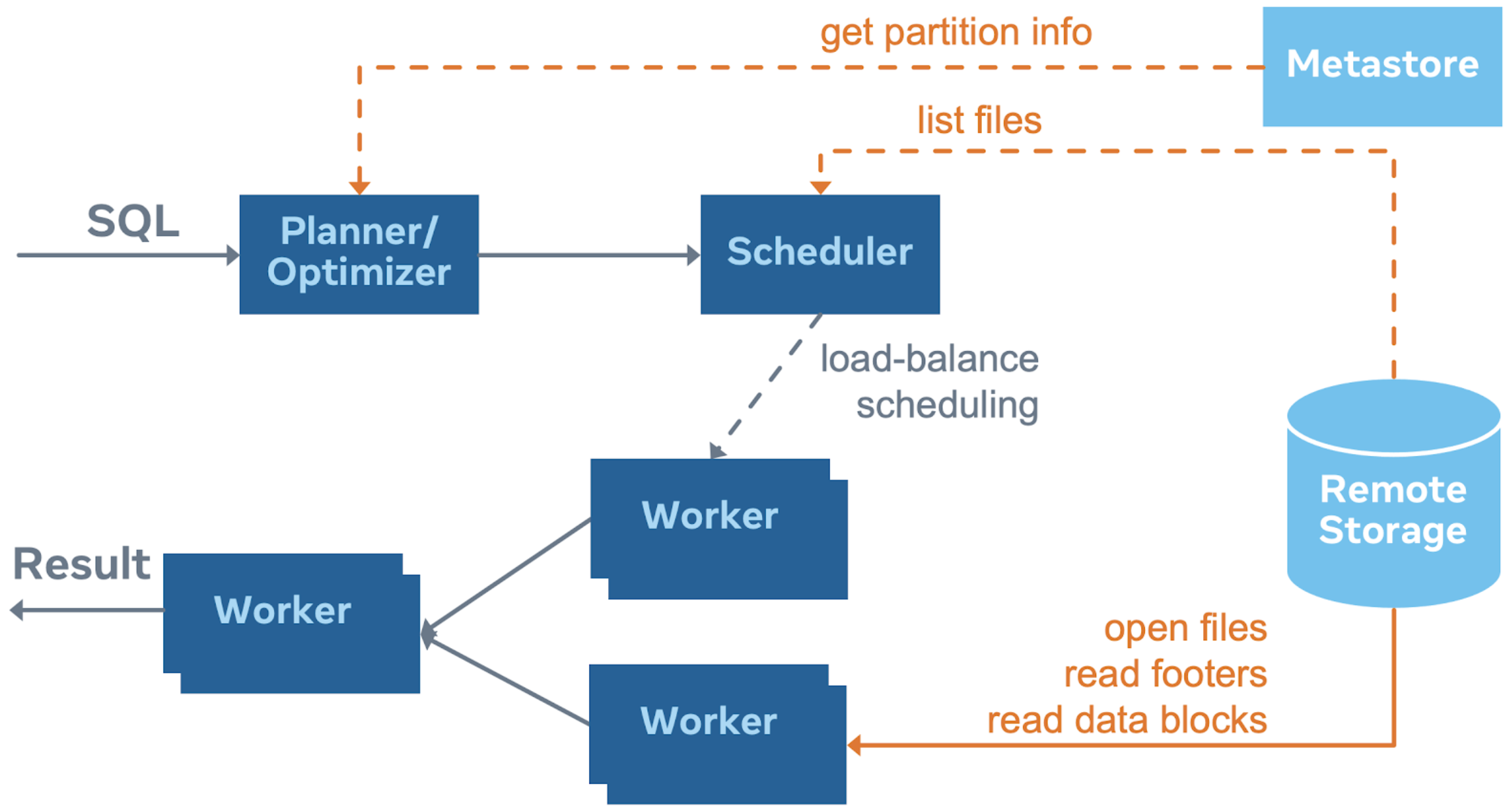
RaptorX: Build a Hierarchical Caching Solution
Historically, to solve the network saturation issue, Presto has a built-in Raptor connector to load data from remote storage to local SSD for fast access. However, this solution is no different from having a shared compute/storage node, which is runs counter to the idea of storage-compute disaggregation. The downside is obvious: either we waste CPU because the SSD in a worker is full or we waste SSD capacity if we are CPU bound. Thus, we started project RaptorX.
RaptorX is an internal project aiming to boost query performance for Presto by at least 10X. Hierarchical caching is the key to RaptorX's success. Cache is particularly useful when storage nodes are disaggregated from compute nodes. The goal of RaptorX is not to create a new connector or product, but a built-in solution so that existing workloads can seamlessly benefit from it without migration. We are specifically targeting the existing Hive connector which is used by many workloads.
The following figure shows the architecture of the caching solution. We have hierarchical layers of cache, which will be introduced in details in the remainder of this post:
- Metastore versioned cache: We cache table/partition information in the coordinator. Given metadata is mutable, like Iceberg or Delta Lake, the information is versioned. We only sync versions with metastore and fetch updated metadata when a version is out of date.
- File list cache: Cache file list from remote storage partition directory.
- Fragment result cache: Cache partially computed result on leaf worker's local SSDs. Pruning techniques are required to simplify query plans as they change all the time.
- File handle and footer cache: Cache open file descriptors and stripe/file footer information in leaf worker memory. These pieces of data are mostly frequently accessed when reading files.
- Alluxio data cache: Cache file segments with 1MB aligned chunks on leaf worker's local SSDs. The library is built from Alluxio's cache service.
- Affinity scheduler: A scheduler that sends sticky requests based on file paths to particular workers to maximize cache hit rate.
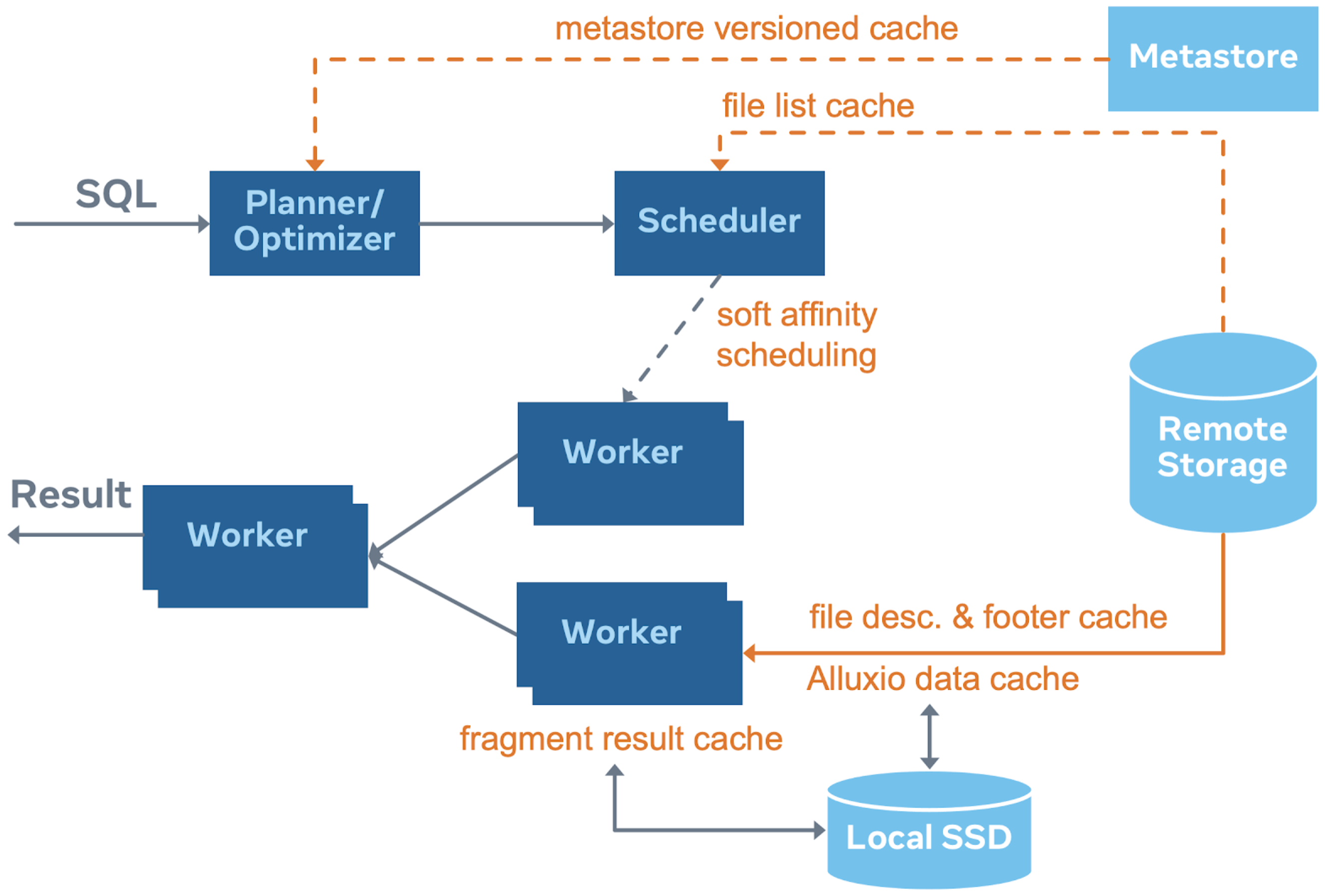
Metastore Versioned Cache
A Presto coordinator caches table metadata (schema, partition list, and partition info) to avoid long getPartitions calls to Hive Metastore. However, Hive table metadata is mutable. Versioning is needed to determine if the cached metadata is valid or not. To achieve that, the coordinator attaches a version number to each cache key-value pair. When a read request comes, the coordinator asks the Hive Metastore to get the partition info (if it's not cached at all) or checks with Hive Metastore to confirm the cached info is up to date. Though the roundtrip to Hive Metastore cannot be avoided, the version matching is relatively cheap compared with fetching the entire partition info.
File List cache
A Presto coordinator caches file lists in memory to avoid long listFile calls to remote storage. This can only be applied to sealed directories. For open partitions, Presto will skip caching those directories to guarantee data freshness. One major use case for open partitions is to support the need of near-realtime ingestion and serving. In such cases, the ingestion engines (e.g., micro batch) will keep writing new files to the open partitions so that Presto can read near-realtime data. Further details like compaction, metastore update, or replication for near-realtime ingestion will be out of the scope of this note.
Fragment Result Cache
A Presto worker that is running a leaf stage can decide to cache the partially computed results on local SSD. This is to prevent duplicated computation upon multiple queries. The most typical use case is to cache the plan fragments on leaf stage with one level of scan, filter, project, and/or aggregation.
For example, suppose a user sends the following query, where ds is a partition column:
SELECT SUM(col) FROM T WHERE ds BETWEEN '2021-01-01' AND '2021-01-03'
The partially computed sum for each of 2021-01-01, 2021-01-02, and 2021-01-03 partitions (or more precisely the corresponding files) will be cached on leaf workers forming a "fragment result". Suppose the user sends another query:
SELECT sum(col) FROM T WHERE ds BETWEEN '2021-01-01' AND '2021-01-05'
Then, the leaf worker will directly fetch the fragment result for 2021-01-01, 2021-01-02, and 2021-01-03 from cache and just compute the partial sum for 2021-01-04 and 2021-01-05.
Note that the fragment result is based on the leaf query fragment, which could be highly flexible as users can add or remove filters or projections. The above example shows we can easily handle filters with only partition columns. In order to avoid the cache miss caused by frequently changing non-partition column filters, we introduced partition statistics based pruning. Consider the following query, where time is a non-partition column:
SELECT SUM(col) FROM T
WHERE ds BETWEEN '2021-01-01' AND '2021-01-05'
AND time > now() - INTERVAL '3' DAY
Note that now() is a function that has values changing all the time. If a leaf worker caches the plan fragment based on now()’s absolute value, there is almost no chance to have a cache hit. However, if predicate time > now() - INTERVAL '3' DAY is a "loose" condition that is going to be true for most of the partitions, we can strip out the predicate from the plan during scheduling time. For example, if today was 2021-01-04, we know for partition ds = 2021-01-04, predicate time > now() - INTERVAL '3' DAY is always true.
More generically, consider the following figure that contains a predicate and 3 partitions (A, B, C) with stats showing min and max. When the partition stats domain does not have any overlap with the predicate domain (e.g. partition A), we could directly prune this partition without sending splits to workers. If the partition stats is completely contained by the predicate domain (e.g. Partition C), then we don’t need this predicate because it would always hold true for this specific partition, and we could strip the predicate when doing plan comparison. For other partitions that have some overlapping with the predicate, we have to scan the partition with the given filter.

File Descriptor and Footer Cache
A Presto worker caches the file descriptors in memory to avoid long openFile calls to remote storage. Also, a worker caches common columnar file and stripe footers in memory. The current supported file formats are ORC, DWRF, and Parquet. The reason to cache such information in memory is due to the high hit rate of footers as they are the indexes to the data itself.
Alluxio Data Cache
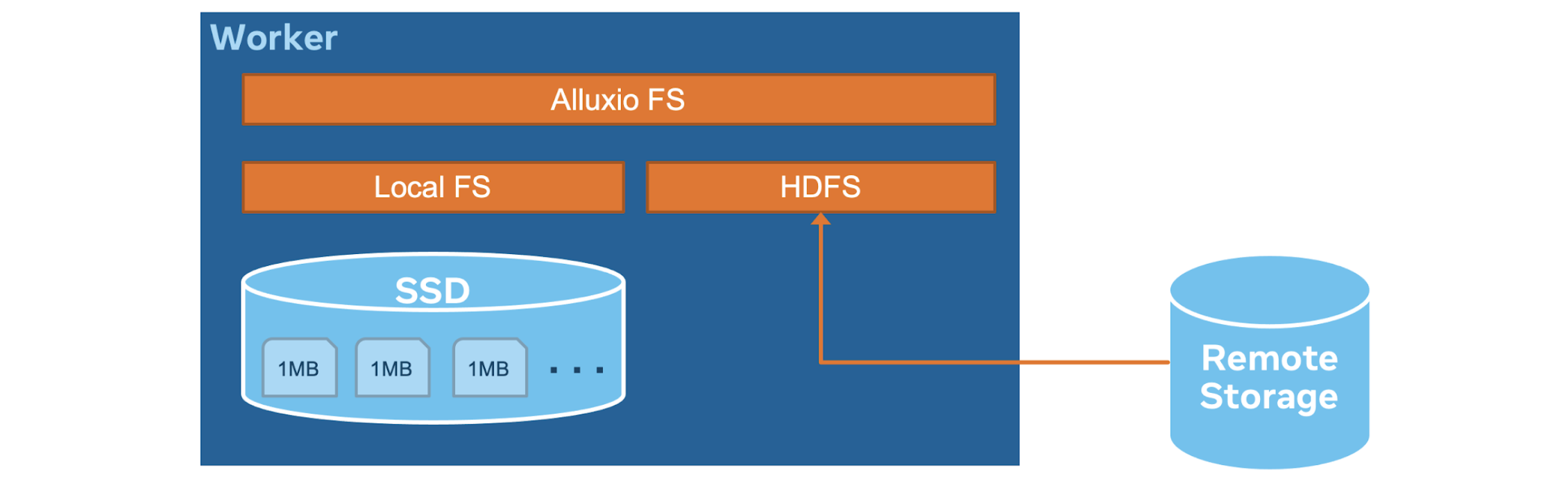
Alluxio data cache has been introduced in an earlier post. It is the main feature to deprecate the Raptor connector. A Presto worker caches remote storage data in its original form (compressed and possibly encrypted) on local SSD upon read. If, in the future, there is a read request covering the range that can be found on the local SSD, the request will return the result directly from the local SSD. The caching library was built as a joint effort with Alluxio and the Presto open source community.
The caching mechanism aligns each read into 1MB chunks, where 1MB is configurable to be adapted to different storage capability. For example, suppose Presto issues a read with 3MB in length starting with offset 0, then Alluxio cache checks if 0 - 1MB, 1 - 2MB, and 2 - 3MB chunks are already on disk and only fetch those that are not cached. The purging policy is based on LRU. It removes chunks from a disk that has not been accessed for the longest time. The Alluxio data cache exposes a standard Hadoop File System interface to the Hive connector, transparently storing requested chunks in a high-performance, highly concurrent, and fault-tolerant storage engine which is designed to serve workloads at Facebook scale.
Soft Affinity Scheduling
To maximize the cache hit rate on workers, the coordinator needs to schedule the requests of the same file to the same worker. Because there is a high chance part of the file has already been cached on that particular worker. The scheduling policy is "soft", meaning that if the destination worker is too busy or unavailable, the scheduler will fallback to its secondary pick worker for caching or just skip the cache when necessary. The same earlier post has a detailed explanation of the scheduling policy. The scheduling policy guarantees that cache is not on the critical path, but still can boost performance.
Performance
RaptorX cache has been fully deployed and battle tested within Facebook. To compare the performance with vanilla Presto, we ran TPC-H benchmark on a 114-node cluster. Each worker has a 1TB local SSD with 4 threads configured per task. We prepared TPC-H tables with a scale factor of 100 in remote storage. The following chart shows the comparison between Presto and Presto with the hierarchical cache.
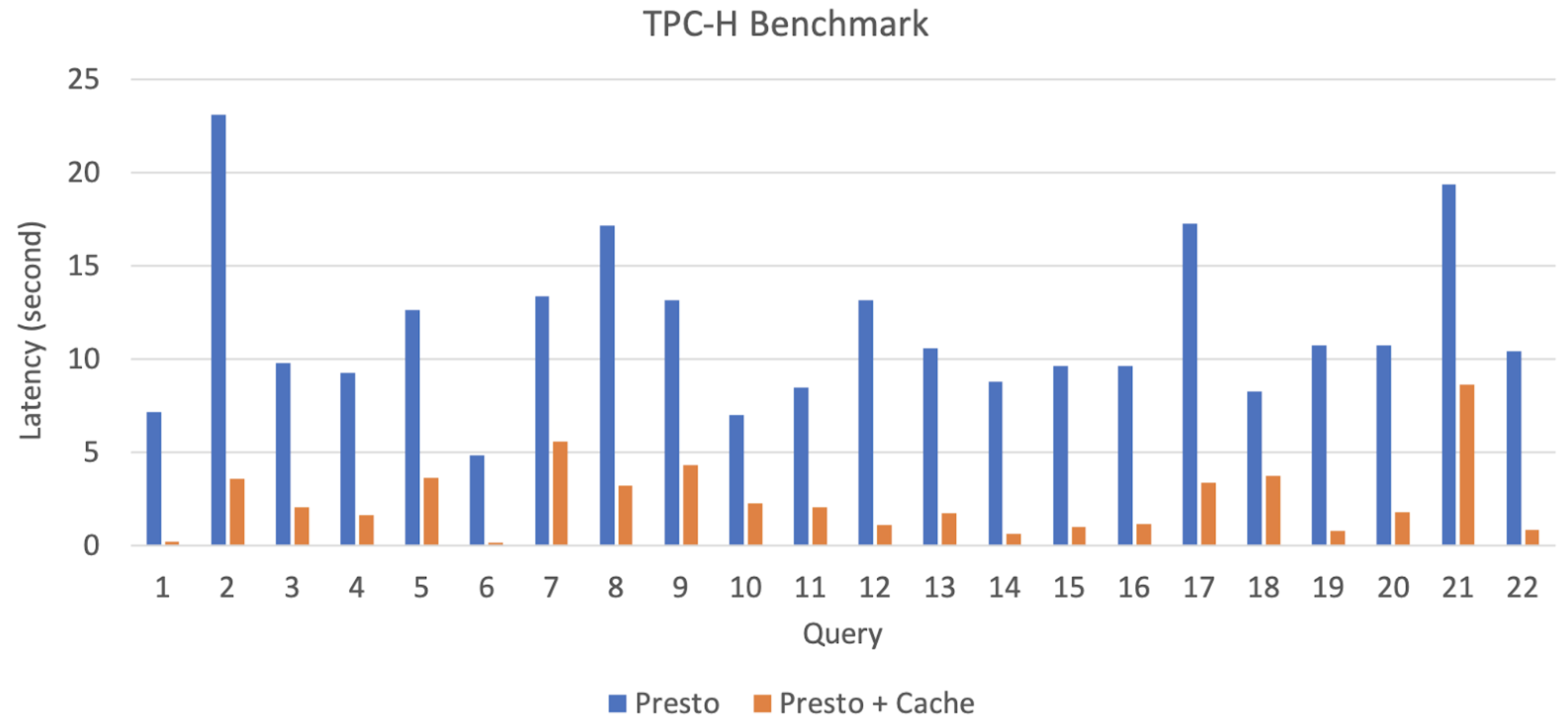
From the benchmark, scan-heavy or aggregation-heavy queries like Q1, Q6, Q12 - Q16, Q19, and Q22 all have more than 10X latency improvement. Even join-heavy queries like Q2, Q5, Q10, or Q17 have 3X - 5X latency improvements.
User Guide
It is required to have local SSDs for workers in order to fully enable this feature. To turn on various layers of the caches in this post, tune the following configs accordingly.
Scheduling (/catalog/hive.properties):
hive.node-selection-strategy=SOFT_AFFINITY
Metastore versioned cache (/catalog/hive.properties):
hive.partition-versioning-enabled=true
hive.metastore-cache-scope=PARTITION
hive.metastore-cache-ttl=2d
hive.metastore-refresh-interval=3d
hive.metastore-cache-maximum-size=10000000
List files cache (/catalog/hive.properties):
hive.file-status-cache-expire-time=24h
hive.file-status-cache-size=100000000
hive.file-status-cache-tables=*
Data cache (/catalog/hive.properties):
cache.enabled=true
cache.base-directory=file:///mnt/flash/data
cache.type=ALLUXIO
cache.alluxio.max-cache-size=1600GB
Fragment result cache (/config.properties and /catalog/hive.properties):
fragment-result-cache.enabled=true
fragment-result-cache.max-cached-entries=1000000
fragment-result-cache.base-directory=file:///mnt/flash/fragment
fragment-result-cache.cache-ttl=24h
hive.partition-statistics-based-optimization-enabled=true
File and stripe footer cache (/catalog/hive.properties):
- For ORC or DWRF:
hive.orc.file-tail-cache-enabled=true
hive.orc.file-tail-cache-size=100MB
hive.orc.file-tail-cache-ttl-since-last-access=6h
hive.orc.stripe-metadata-cache-enabled=true
hive.orc.stripe-footer-cache-size=100MB
hive.orc.stripe-footer-cache-ttl-since-last-access=6h
hive.orc.stripe-stream-cache-size=300MB
hive.orc.stripe-stream-cache-ttl-since-last-access=6h
- For Parquet:
hive.parquet.metadata-cache-enabled=true
hive.parquet.metadata-cache-size=100MB
hive.parquet.metadata-cache-ttl-since-last-access=6h