Native Parquet Writer for Presto
Pinterest: Lu Niu
Twitter: Zhenxiao Luo
Overview
With the wide deployment of Presto in a growing number of companies, Presto is used not only for queries, but also for data ingestion and ETL jobs. There is a need to improve Presto’s file writer performance, especially for popular columnar file formats, e.g. Parquet, and ORC. In this article, we introduce the brand new native Parquet writer for Presto, which writes directly from Presto's columnar data structure to Parquet's columnar values, with up to 6X throughput improvement and less CPU and memory overhead.
Presto’s Old Parquet Writer
As shown in Figure 1, Presto was using Hive’s old Parquet writer to write files: This old approach first iterates each columnar block in a page and reconstructs every single record. Then Presto would call the Hive record writer to consume each individual record and write value bytes to Parquet pages. Whenever it exceeds the buffer size, the old writer will flush in memory data to the underlying file system.
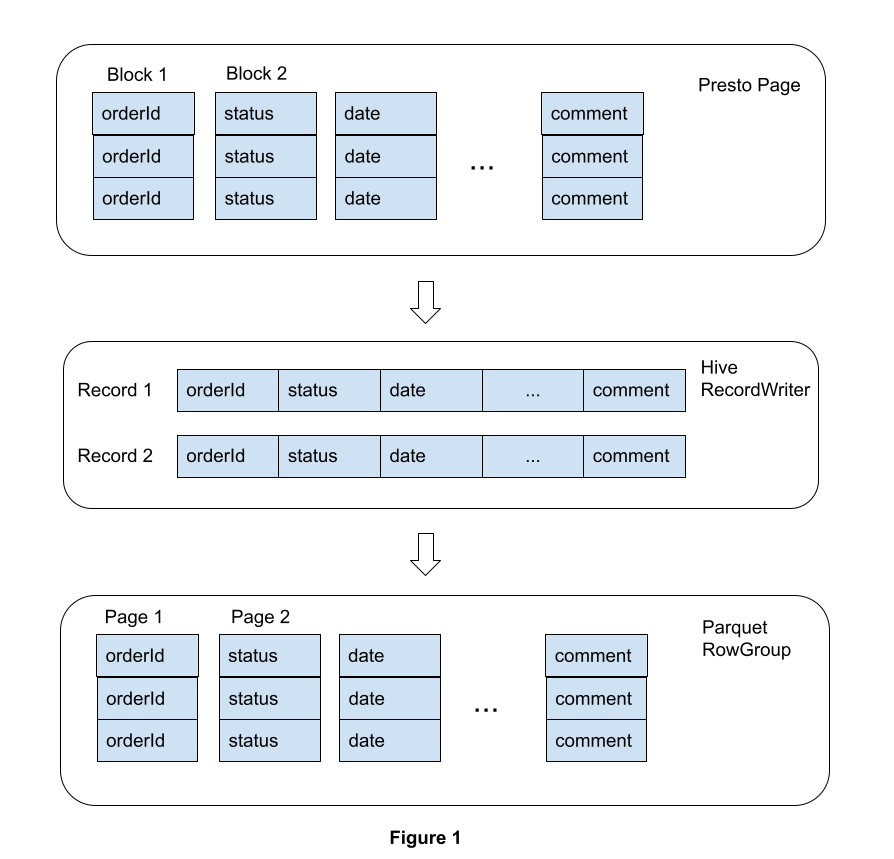
Presto has vectorized execution for in-memory columnar data, and Parquet is a columnar file format. The old Parquet writer was adding unnecessary overhead to convert Presto’s columnar in-memory data into row based records, and then doing one more conversion to write row based records to Parquet’s columnar on disk file format. The unnecessary data transformation adds significant performance overhead, especially when complex data types are involved such as nested structs.
Brand New Native Parquet Writer
To improve file writing efficiency, and overcome drawbacks in the old Parquet writer, we are introducing a brand new native Parquet writer, which writes directly from Presto's in-memory data structure to Parquet's columnar file format, including data values, repetition values, and definition values. The native Parquet writer significantly reduces CPU and memory overhead for Presto.
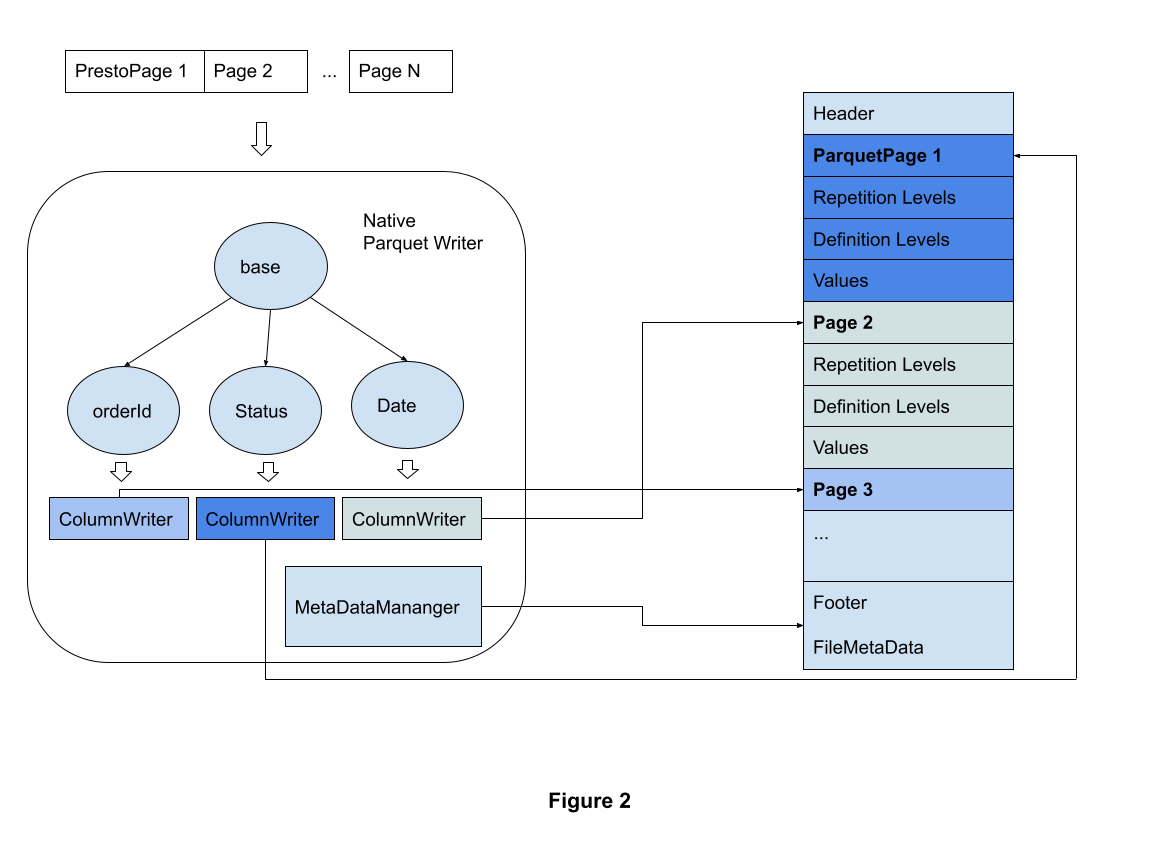
As shown in figure 2, the native Parquet writer constructs Parquet schema based on column names and types. Primitive types and complex types(Struct, Array, Map) are converted to corresponding Parquet types. Column writers are created with schema information. For each Presto page, the native writer iterates each block, transforming the Presto block into Parquet values, definition levels, and repetition levels. The corresponding column writer will write byte streams into a Parquet file.
Performance
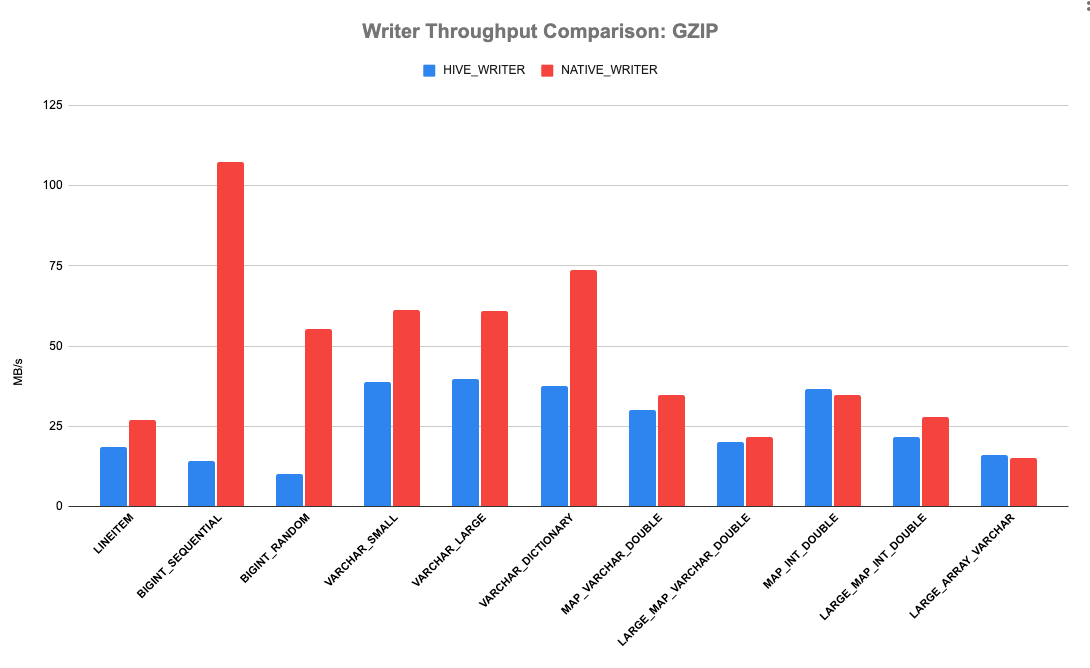
Presto has a Hive file format benchmark to test reader and writer performance. The test creates a list of pages containing millions of rows, writes them to a temp file using either the native writer or the old hive record writer and then compares the performance. The following graphs show the results with three compression schemes: gzip, snappy and no compression. X-axis are various types of data; Y-axis are writing throughput. Clearly, we could see the brand new native Parquet writer outperforms the old writer. It could consistently achieve > 20% throughput improvements. The native Parquet writer performs best for BIGINT_SEQUENTIAL and BIGINT_RANDOM with GZIP compression, with up to 650% throughput improvements. When writing all columns of TPCH LINEITEM, the throughput gain is around 50%.
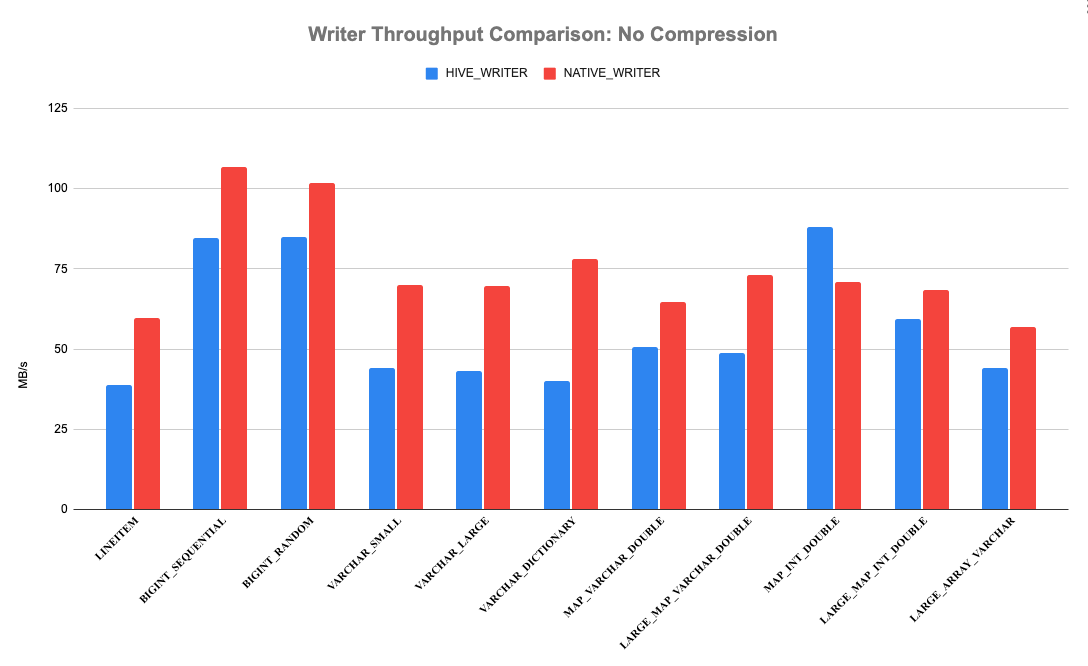
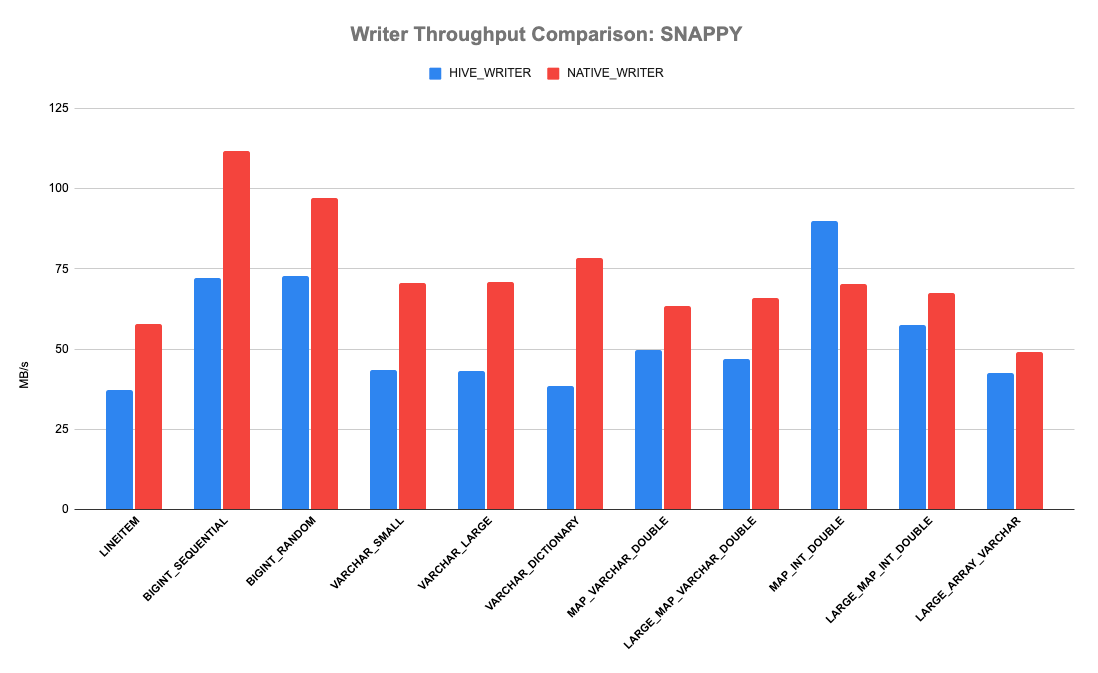
Use Native Parquet Writer in Production
The native parquet writer is ready for production deployment. To turn it on:
# in /catalog/hive.properties
hive.parquet.optimized-writer.enabled=true
If you have any questions, feel free to ask in the PrestoDB Slack Channel.