Native Delta Lake Connector for Presto
Co-authors
Denny Lee, Sr. Staff Developer Advocate at Databricks
This is a joint publication by the PrestoDB and Delta Lake communities

Due to the popularity of both the PrestoDB and Delta Lake projects (more on this below), in early 2020 the Delta Lake community announced that one could query Delta tables from PrestoDB. While popular, this method entailed the use of a manifest file where a Delta table is registered in Hive metastore as symlink table type. While this approach may satisfy batch processing requirements, it did not satisfy frequent processing or streaming requirements. Therefore, we are happy to announce the release of the native Delta Lake connector for PrestoDB (source code | docs).

Before we dive into the connector, let’s provide some background for those not intimately familiar with these projects.
Presto - Open Source SQL Engine for the Data Lakehouse
Presto is an open source, MPP, distributed SQL engine widely recognized for its low latency queries, high concurrency and native ability to query data lakes and many other data sources. Presto is a compute layer of the disaggregated stack which allows users to scale storage and compute separately and as cloud adoption has increased exponentially, Presto has become the de facto query engine for interactive analytical queries.
Why Does It Matter?
As cloud data warehouses become more cost prohibitive, and data mesh approach is not performant enough, more and more workloads are migrating to the data lake. If all your data is going to end up in cloud native storage like Amazon S3, ADLS Gen2, GCS, etc. then the most optimized and efficient data strategy is to leverage an open data lakehouse analytics stack, which provides much more flexibility with no lock-in.
Delta Lake - Open Source Data Lake Storage Standards
Delta Lake is an open-source project built for data lakehouses with compute engines including Spark, PrestoDB, Flink, and Hive and APIs for Scala, Java, Rust, Ruby, and Python. Delta Lake is an ACID table storage layer over cloud object stores that Databricks started providing to customers in 2017 and open sourced in 2019. The core idea of Delta Lake is simple: it maintains information about which objects are part of a Delta table in an ACID manner, using a write-ahead log that is itself stored in the cloud object store. The objects themselves are encoded in Parquet, making it easy to write connectors from engines that can already process Parquet. This design allows clients to update multiple objects at once, replace a subset of the objects with another, etc., in a serializable manner while still achieving high parallel read and write performance from the objects themselves (similar to raw Parquet). The log also contains metadata such as min/max statistics for each data file, enabling an order of magnitude faster metadata searches than the “files in object store” approach.
Delta Lake is designed so that all the metadata is in the underlying object store, and transactions are achieved using optimistic concurrency protocols against the object store (with some details varying by cloud provider). This means that no servers need to be running to maintain state for a Delta table; users only need to launch servers when running queries, and enjoy the benefits of separately scaling compute and storage. For more information, refer to the VLDB whitepaper Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores.
Native Delta Lake Connector
We - the Presto and Delta Lake communities - have come together to make it easier for Presto to leverage the reliability of data lakes by integrating with Delta Lake.
We're excited to announce the addition of the Native Delta Lake Connector feature which allows for the reading of Delta Lake tables natively in Presto instead of using a manifest file (symlink_format_manifest).
This enhances the Open Data Lake Analytics Experience with Presto, offering:
- Robust data consistency
- Automatic schema evolution
- More memory performance with an iterator
- No additional manual intervention
- Time travel query support
- Data skipping (as part of the Delta Lake 2022H1 roadmap)
- File statistics (as part of the Delta Lake 2022H1 roadmap)
This Presto/Delta connector utilizes the Delta Standalone project to natively read the Delta transaction log without the need of a manifest file. The memory-optimized, lazy iterator included in Delta Standalone allows PrestoDB to efficiently iterate through the Delta transaction log metadata and avoids OOM issues when reading large Delta tables.
Architecture
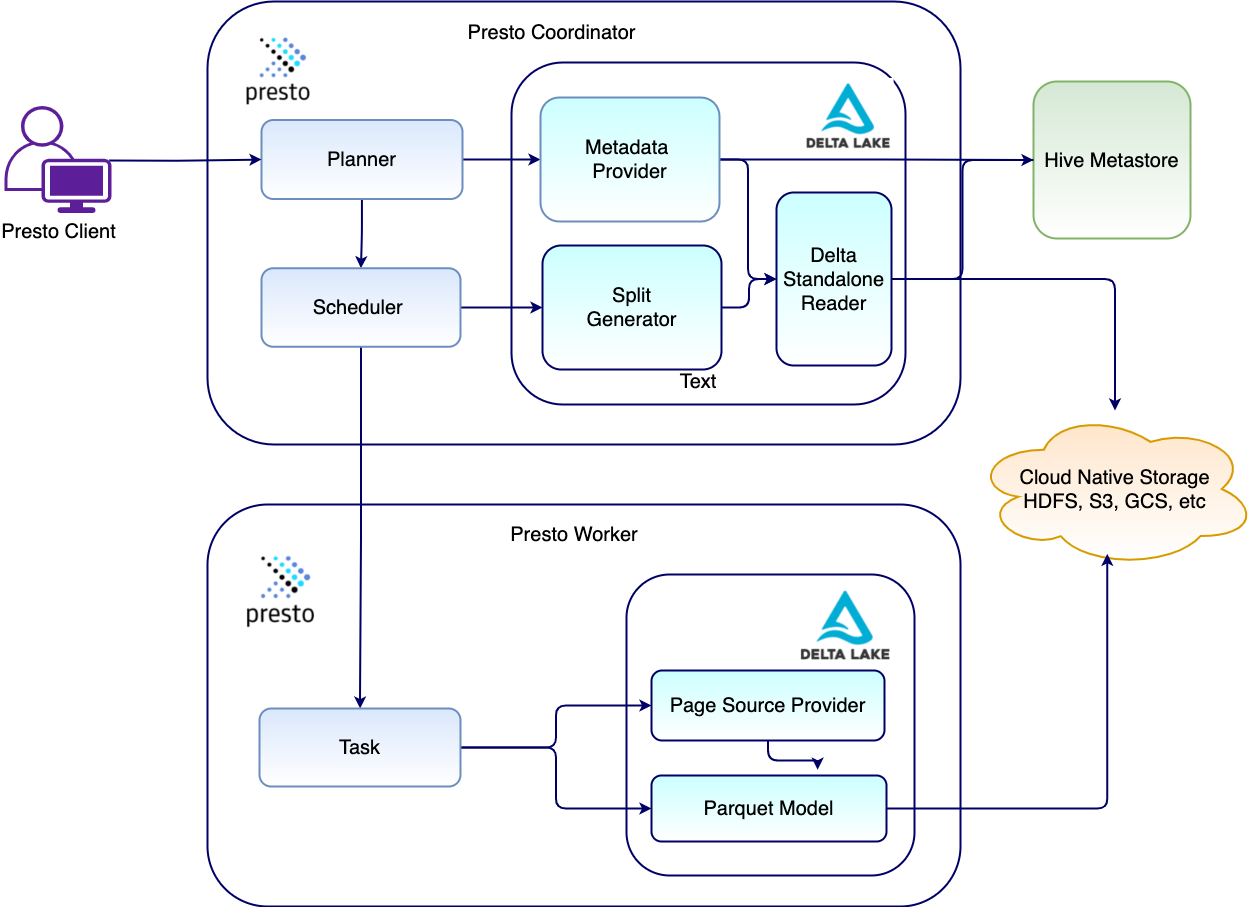
Figure 1: This diagram illustrates the flow of calls between Presto main, Delta connector, Delta Standalone Reader (DSR) library, Hive Metastore (HMS) and Storage at Presto Coordinator and Executors
Presto consists of two types of processes, Coordinator and Worker.
- Presto Coordinator is responsible for receiving the query from the client, parsing, planning, optimizing, scheduling tasks and managing workers to execute queries and sending query output back to the client.
- Presto Worker is responsible for executing tasks and processing data.
Delta Lake Connector consists of following main components:
- Metadata Provider: As the name says Metadata Provider is responsible for discovery of Delta Lake tables either through Hive Metastore or table path in storage and loading Delta table metadata using Delta Standalone Reader library which stores in its own transaction logs.
- Delta Standalone Reader: This is a library used to get the list of files (that pass the predicate) from the snapshot. The predicate (if present) may contain filters on partition columns and/or regular columns. The DSR library takes care of filtering the files based on the predicate and partition columns (and in future can use file stats to prune even more files). Each file maps one split and in addition to the file path, the split also contains the predicate which is used in data skipping at the reader (eg. Parquet RowGroup skipping or Page skipping)
- Split Generator: Split Generator splits the table into multiple input splits. Splits are generated in batches with help of DSR's lazy iterator. Once the first batch is received, the tasks are started by the Scheduler. As the tasks read the first batch of splits, the next set of splits is generated by the Split Generator.
- Page Source Provider: In Delta connector implementation, existing Parquet reader implementation is used to create a Page Source. The Parquet PageSource takes the file path, list of columns to read and predicate from the Split generated by Delta Split Generator. The predicate is used to prune row groups based on the row group stats. As we add support for other file formats, there is a need to create PageSource for that format.
Implementation: Querying Delta Lake tables from Presto
This native connector is available by default with your Presto installation. Here “delta” is the Delta Lake catalog name.
Accessing Delta Table with table name from Presto:
presto> describe delta.default.nation_location;
presto> describe delta.default.nation_location;
Column | Type | Extra | Comment
-----------+---------+-------+---------
nationkey | bigint | |
name | varchar | |
regionkey | bigint | |
comment | varchar | |
(4 rows)
Query 20220204_073639_00009_edx3y, FINISHED, 3 nodes
Splits: 68 total, 68 done (100.00%)
0:24 [4 rows, 299B] [0 rows/s, 12B/s]
Directly querying Delta Lake table path - access delta table with its S3 file path
presto> select * from delta."$path$"."s3://delta-glue/nation_data" limit 2;
presto> select * from delta."$path$"."s3://delta-glue/nation_data" limit 2;
nationkey | name | regionkey | comment
-----------+-----------+-----------+------------------------------------------------------------------------------
0 | ALGERIA | 0 | haggle. carefully final deposits detect slyly agai
1 | ARGENTINA | 1 | al foxes promise slyly according to the regular accounts. bold requests alon
(2 rows)
Query 20220204_073347_00005_edx3y, FINISHED, 2 nodes
Splits: 34 total, 34 done (100.00%)
0:14 [3 rows, 1.68KB] [0 rows/s, 123B/s]
Snapshot Access
Query version 1 of this table
presto> WITH nyctaxi_2019_part AS (SELECT * FROM deltas3."$path$"."s3://weyland-yutani/delta/nyctaxi_2019_part@v1") SELECT COUNT(1) FROM nyctaxi_2019_part;
_col0
----------
59354546
(1 row)
Query version 5 of this table
presto> WITH nyctaxi_2019_part AS (SELECT * FROM deltas3."$path$"."s3://weyland-yutani/delta/nyctaxi_2019_part@v5") SELECT COUNT(1) FROM nyctaxi_2019_part;
_col0
----------
78959576
(1 row)
Query current version of this table
presto> WITH nyctaxi_2019_part AS (SELECT * FROM deltas3."$path$"."s3://weyland-yutani/delta/nyctaxi_2019_part") SELECT COUNT(1) FROM nyctaxi_2019_part;
_col0
----------
84397753
(1 row)
What’s next?
Try out the PrestoDB and Delta Lake connector! Here are some more resources to help you get started:
- Source code
- Public documentation
- Presto/Delta Lake Community Office hours
- Delta Standalone project
- PrestoCon 2021 presentation
If you find any issues with the connector, please open up an issue in the PrestoDB GitHub or Delta Lake Connectors GitHub. If you have questions, please join the presto-users discussion list, PrestoDB Slack channel, Delta Lake discussion list, or Delta Lake Slack channel.
Credit
We would also like to thank the PrestoDB and Delta Lake communities with special call out to Venki Korukanti, Sajith Appukuttan, and George Chow.