Disaggregated Coordinator
Meta: Swapnil Tailor, Tim Meehan, Vaishnavi Batni, Abhisek Saikia, Neerad Somanchi
Overview
Presto's architecture originally only supported a single coordinator and a pool of workers. This has worked well for many years but created some challenges.
- With a single coordinator, the cluster can scale up to a certain number of workers reliably. A large worker pool running complex, multi-stage queries can overwhelm an inadequately provisioned coordinator, requiring upgraded hardware to support the increase in worker load.
- A single coordinator is a single point of failure for the Presto cluster.
To overcome these challenges, we came up with a new design with a disaggregated coordinator that allows the coordinator to be horizontally scaled out across a single pool of workers.
Architecture
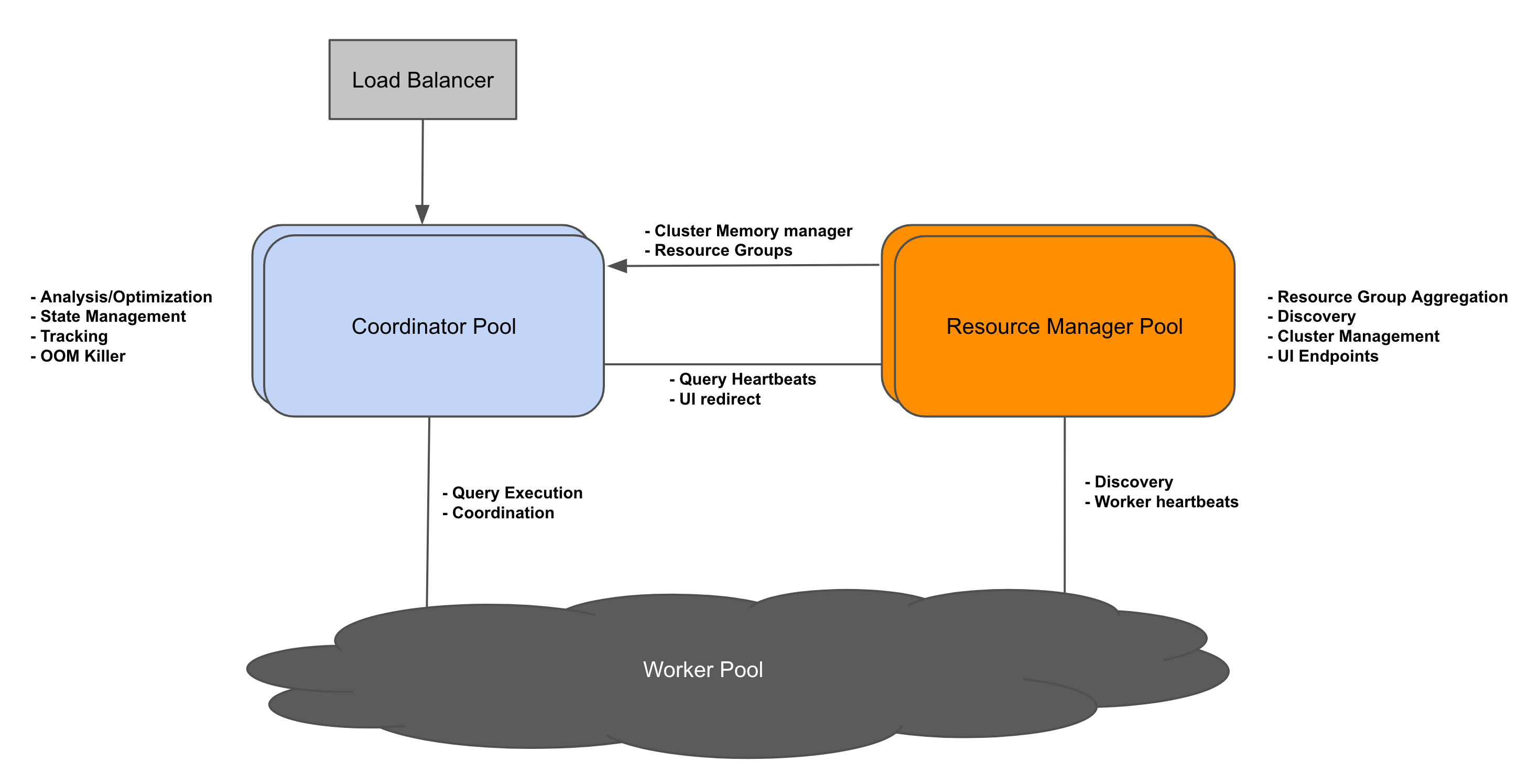
A disaggregated coordinator setup supports a pool of coordinators with the help of a new component, the resource manager.
Resource Manager
The resource manager aggregates data from all coordinators and workers, and constructs a global view of the cluster. Clusters support multiple resource managers, each acting as a primary. The discovery service runs on each resource manager. The resource manager is not in the critical path for the query. Rather, it is a complementary process that can survive momentary unavailability.
Coordinator
The coordinator sends heartbeats at regular intervals to all the resource managers. These heartbeats contain information about the queries handled by the coordinator, which the resource managers use to refresh their global view of the cluster. The coordinator fetches aggregated resource group information periodically from the resource manager.
Worker
Each worker sends regular heartbeats with memory and cpu utilization to the resource managers. The resource managers track these metrics for the worker pool.
Query Execution Flow
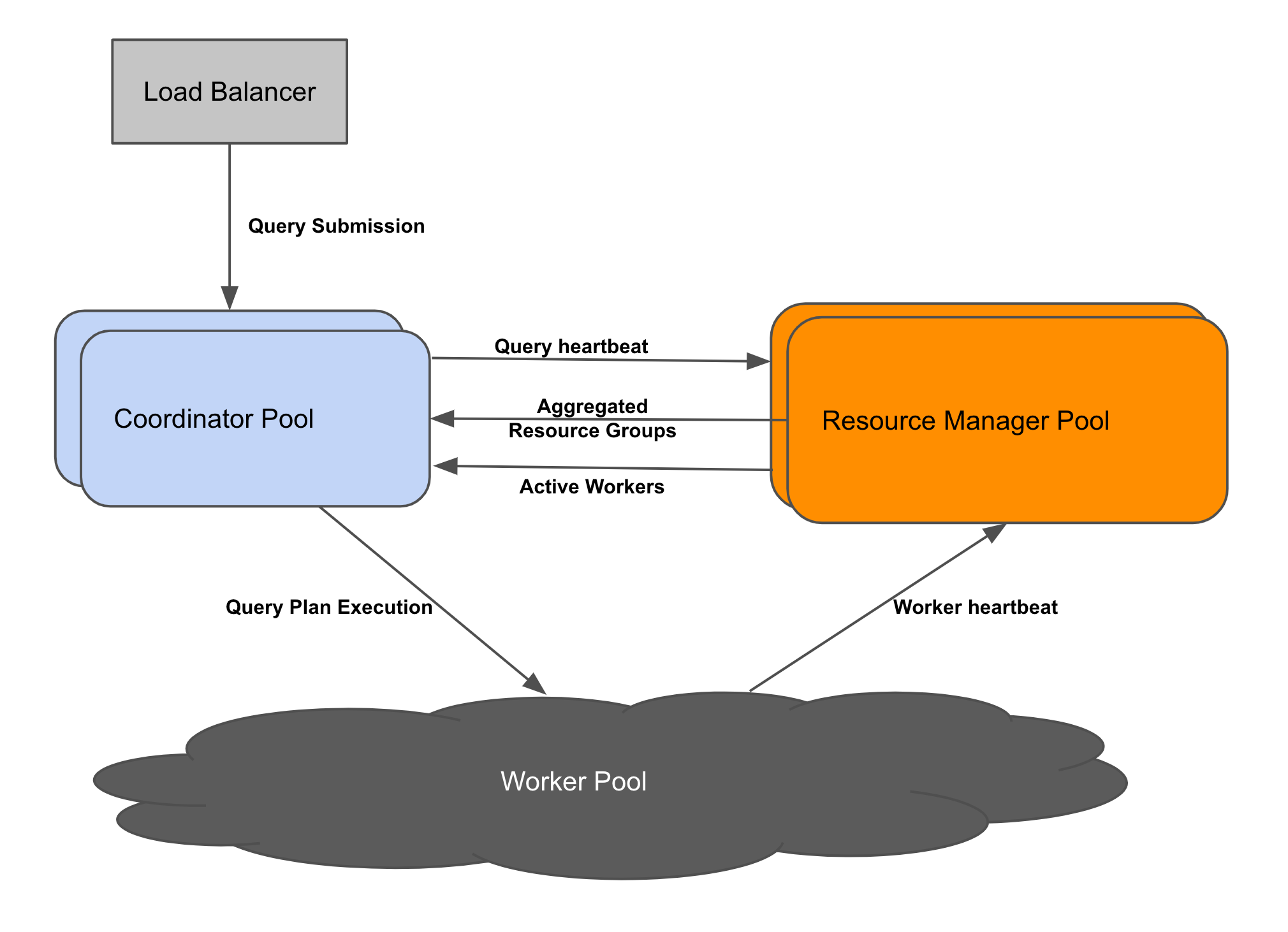
With the introduction of a resource manager, the query execution flow looks slightly different.
- A query is submitted to one of the coordinators in the cluster.
- The coordinator prepares the query for execution by parsing, analyzing and assigning it to a given resource group.
- A heartbeat is sent to each resource manager when the query is created by the coordinator.
- The coordinator polls the resource manager at regular intervals to fetch cluster level resource group information.
- The coordinator polls the resource manager to get active worker information. This information is used for query scheduling.
- The rest of the query execution remains the same.
Memory Management
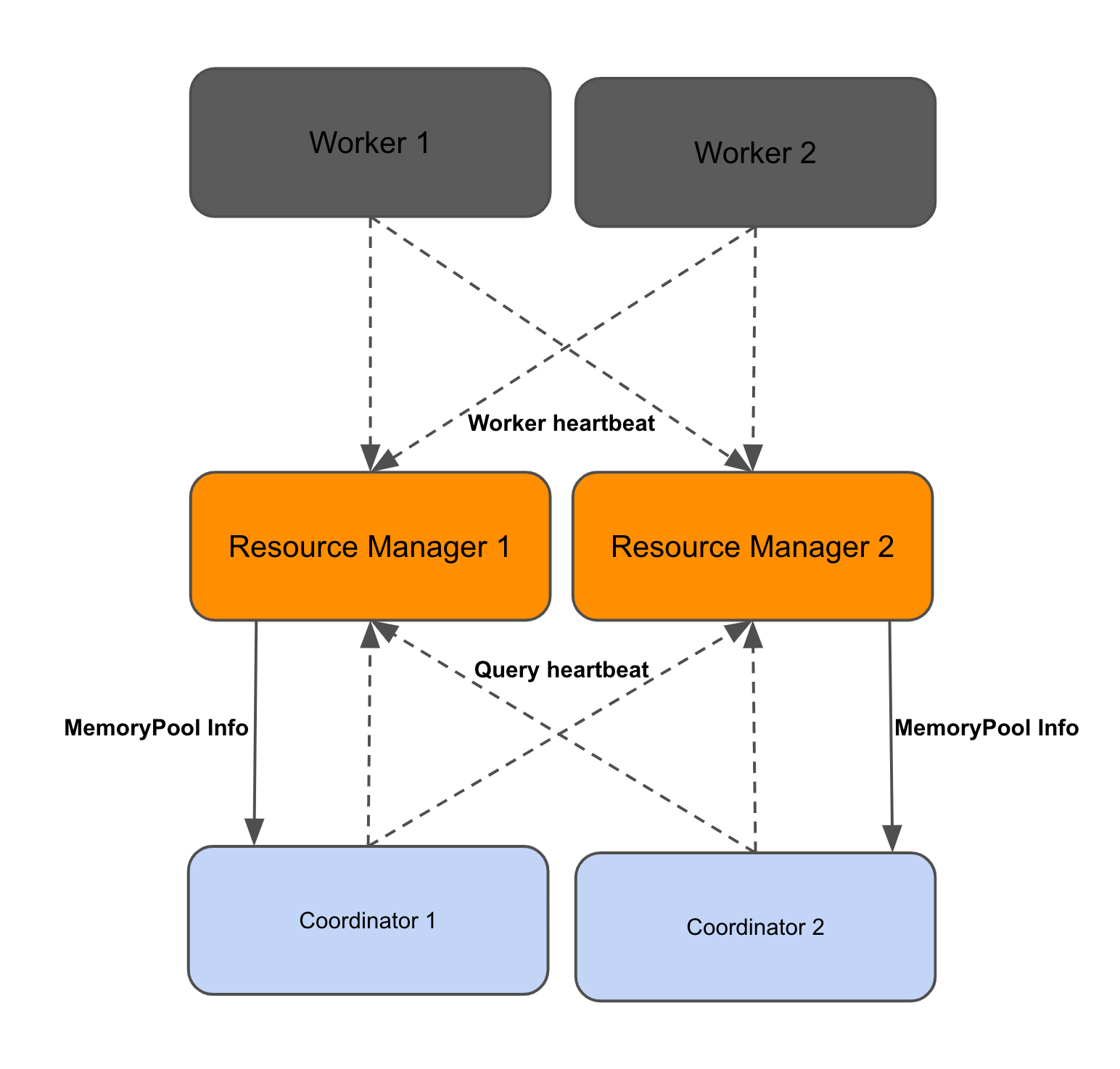
The resource manager needs up to date information about memory and cpu utilization of the worker pool for resource group queuing. Currently, this information is periodically collected by the coordinator. In the disaggregated coordinator setup, resource managers receive query-level statistics from coordinator heartbeats, and memory pool information from worker heartbeats. This information is periodically polled by the coordinator to help make local decisions (i.e. queue/run a query, kill a query when the cluster is low on memory).
Resource Management
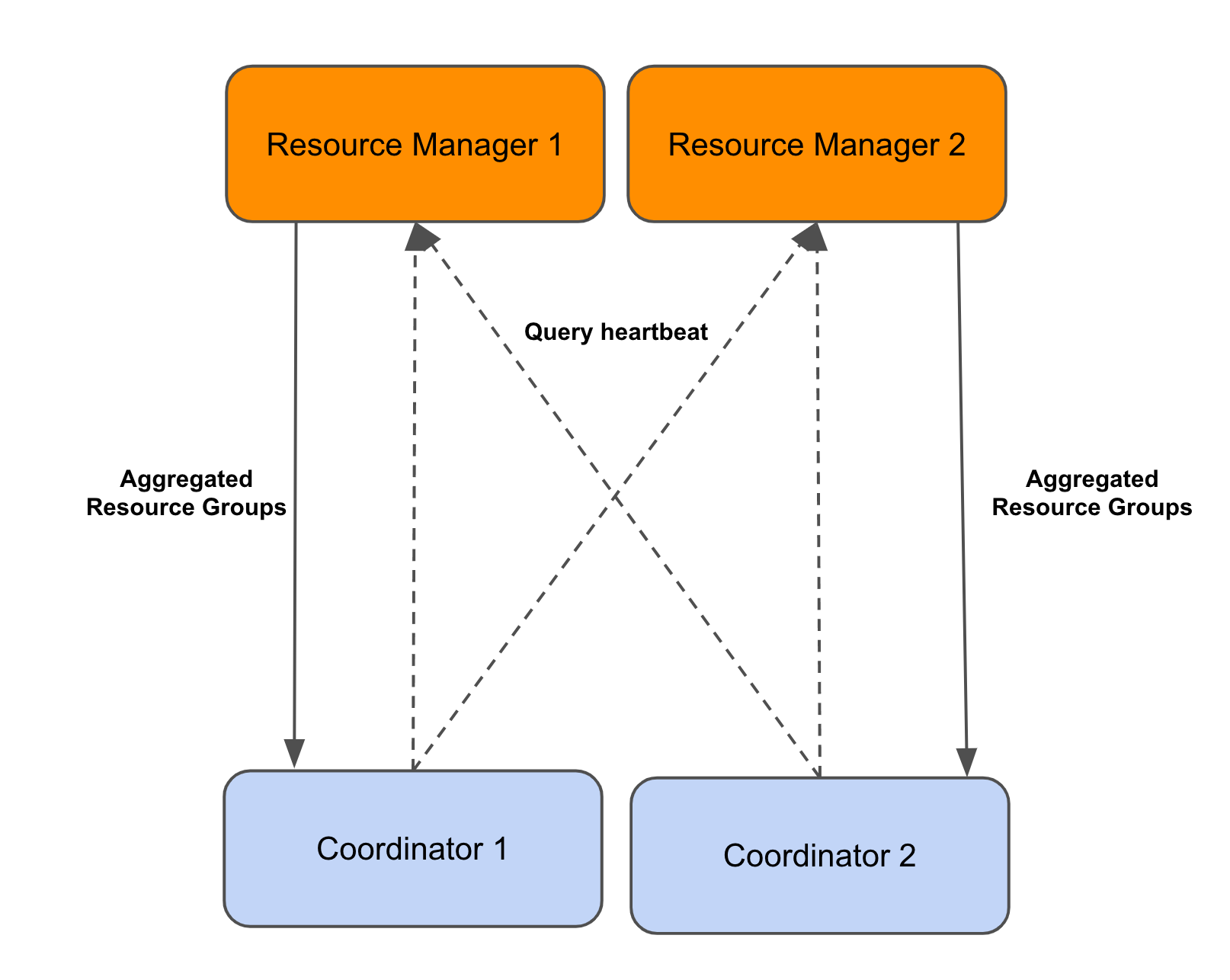
The resource managers runs in multi-master mode. To support that, coordinators post query updates to all resource managers. The resource manager aggregates this information. The coordinator polls a resource manager to fetch up to date information about resource group usage in the cluster.
Resource Group Consistency Model
Resource groups in a disaggregated coordinator setup are eventually consistent. While this may lead to over-admission in certain scenarios, in practice this is mitigated by gating the resource group to only allow queries to run when certain freshness guarantees have been met (as opposed to the previous logic of checking every millisecond). This may mean if the cluster’s resource managers are down, then queries may be queued in the coordinator’s resource groups. This is to ensure coordinators don’t over-admit queries in the face of resource manager unavailability.
More details about flags can be found here which can help tune the cluster’s resource groups to the desired consistency.
Discovery Service
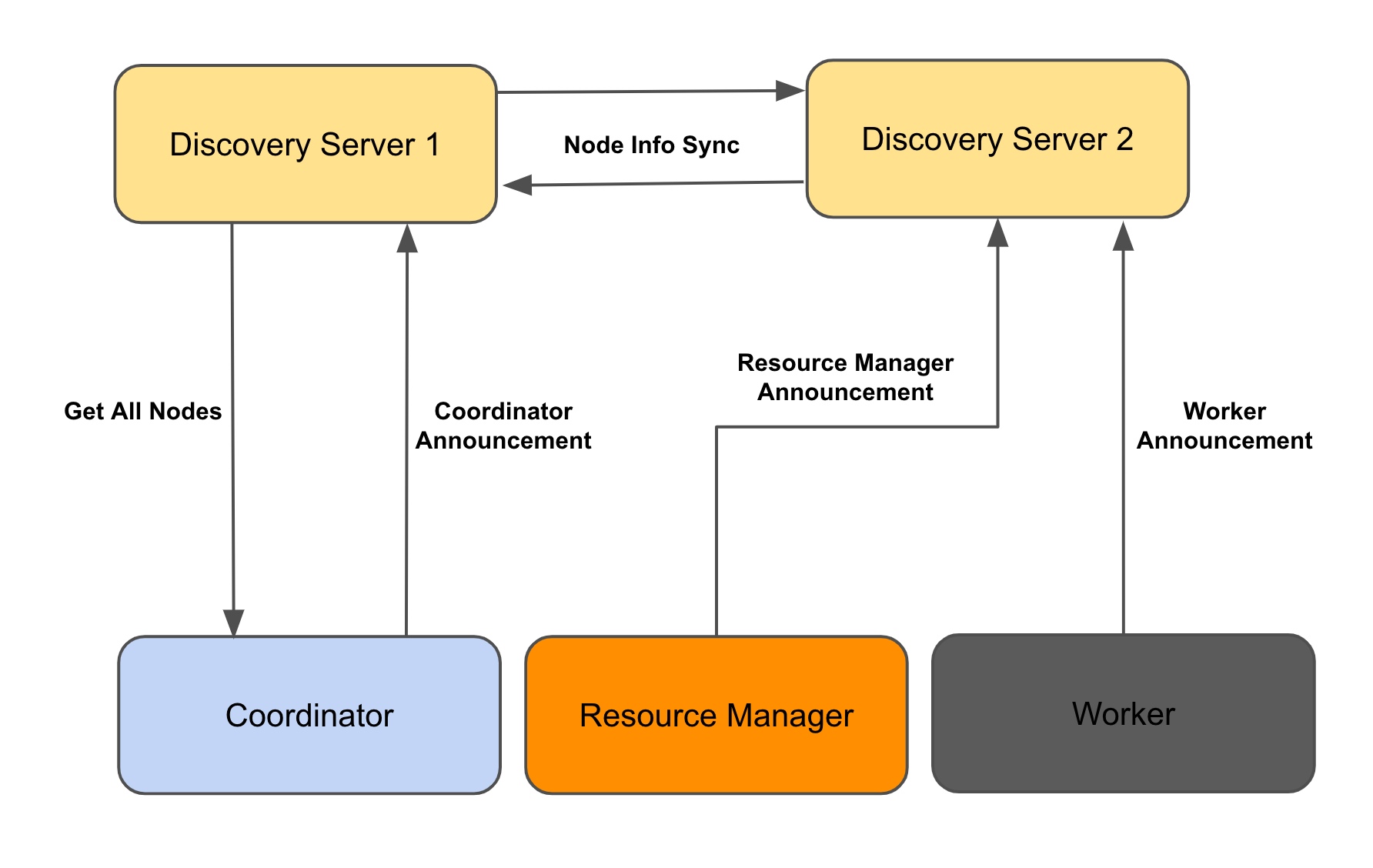
An embedded version of the discovery server runs on resource managers in distributed mode. Discovery servers stay in sync by passing updates they receive to other discovery servers in the cluster.
Configuration
Minimal configuration to enable a disaggregated coordinator cluster can be found in here.
No changes needed in jvm.config and node.properties.
Recommended release version to use disaggregated coordinator in production: 0.266
Disaggregated Coordinator Talk
There were lightning talks about the Disaggregated Coordinator at past PrestoCons. Videos and slides can be accessed using the following links:
Lightning Talk in 2020 Prestocon: video
Lightning Talk in 2021 PrestoCon about Production Rollout: video and slides