Presto on AWS at Twilio - Lesson Learned and Optimization
Earlier this month we hosted PrestoCon, a fantastic in-person event that showcased the innovation around the Presto project. In this blog we’ll detail Twilio’s presentation on their Presto use case, including their architecture, key optimizations, and lessons learned. You can also check out their full presentation here.
In their session, Twilio engineers Aakash Pradeep and Bardi Tripathy covered their data lake evolution journey, the current data scale, the role of Presto in the data ecosystem at Twilio, the current query challenges, and optimization techniques.

If you don’t know, Twilio is a customer engagement platform that allows businesses to connect with their customers through various APIs and channels of communication. Some of these channels include messaging, voice, and contact center APIs. One example of a company that uses Twilio's data platform for text messages and calls is Uber. In addition, many banking authentication and notification text messages are powered by Twilio. The large volume of data generated by these products is stored in a data lake and data warehouse for use in finance, marketing, and sales analytics.
At Twilio, the data lake journey is a key part of the company's operations. Approximately 80% of Twilio's data comes from product teams that use Kafka or MySQL databases. In addition to this, the company receives data from external sources such as Salesforce, Zendesk, and Marketo, as well as internal CSV files generated by accounting and finance teams. This data is loaded into the S3 data lake using config-driven Python and Spark-based loaders. This process allows Twilio to store and process large amounts of data for various analytical use cases.
“we used to load this data into a Redshift data lake for analytical queries and business use cases, with Looker or other dashboarding BI tools on top. However, once our data grew beyond 5 petabytes, we began to face issues with managing Redshift at scale... which led to either capping our costs or experiencing a hit on performance. This is where Presto came in as a solution.”
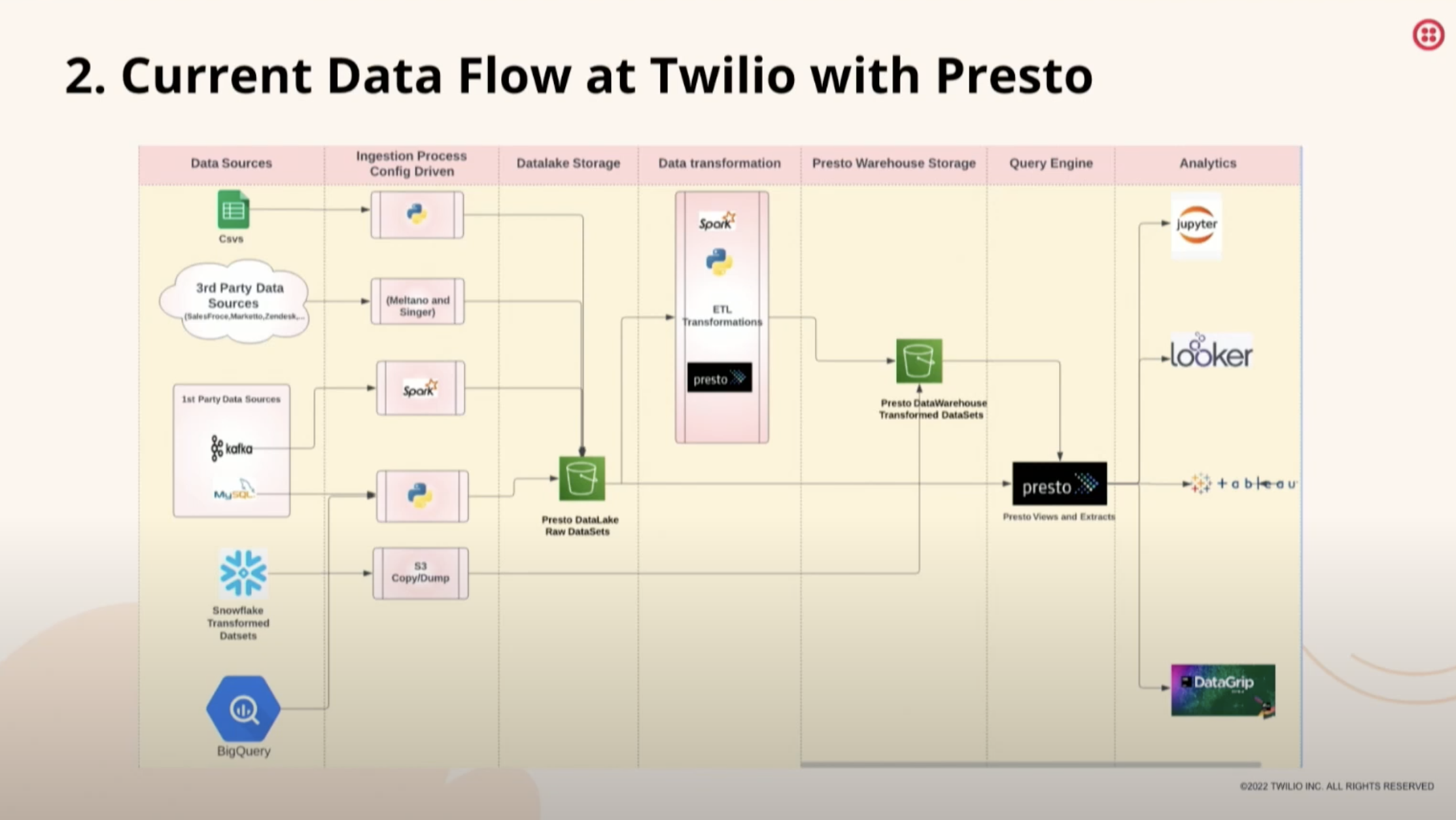
Prior to 2021, Twilio loaded its data into a Redshift data lake for analytical queries and business use cases, using dashboarding BI tools such as Looker. However, as the data grew beyond 5 petabytes, the company encountered challenges in managing Redshift at scale. To address these issues, Twilio implemented Presto, which allowed it to decouple the storage and compute layers and scale without affecting performance. In addition to data exploration and ad-hoc analysis by data analysts, Presto has also been used as a data source for real-time dashboards and machine learning models.
Currently, Twilio is operating at around 10 petabytes of data in its S3 data lake and serving around 500 million queries per day through Presto. This has helped the company significantly in terms of cost optimization, as it no longer has to maintain two copies of data (one in S3 and one in Redshift) and can scale Presto clusters as needed.

As with any large-scale data platform, Twilio has implemented various optimization techniques to ensure efficient operation. These techniques include query scheduling and concurrency controls to prioritize high-impact queries and prevent overloading of the clusters, as well as query caching and data skip strategies to improve the performance of recurring and small queries. Twilio has also implemented hierarchical resource management in Presto, which allows it to define different groups and subgroups with limits on the amount of memory they can use, the number of queries they can run in parallel, and the number of queries they can queue. The company operates multiple clusters, each with different use cases, so it can tune them separately. Additionally, Twilio has implemented guardrails using event listeners in Presto to filter out or kill inefficient or duplicate queries, and to collect and store metadata about queries in a Presto table for further analysis.
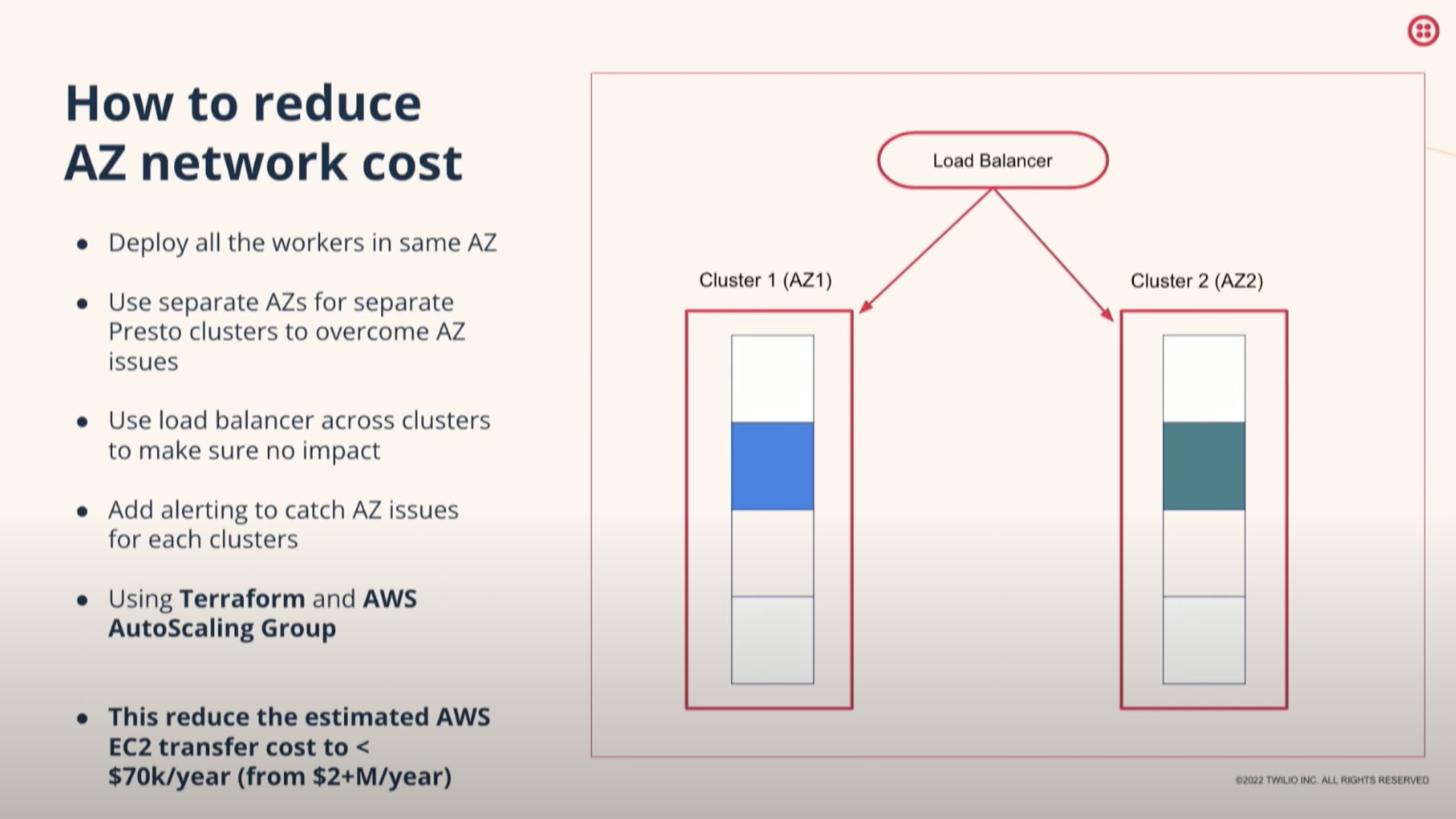
To further optimize the system, Twilio has enabled compression in Presto, which has resulted in a 30% reduction in cost and improved performance for some queries. The company has also evaluated the use of AWS transfer and found that deploying a single Presto cluster in one Availability Zone (AZ) is more stable and cost-effective than attempting to be AZ-agnostic. To ensure reliability, Twilio has implemented a load balancer with multiple clusters in separate AZs and has utilized AWS Auto Scaling Groups to monitor the performance of its clusters. It has also enabled Presto JMX metrics and custom metrics through event listeners to track the performance of its queries and has set up alerts for issues such as insufficient capacity or unhealthy nodes. These optimization techniques have helped Twilio maintain the performance and reliability of its data platform.
We’re excited to see the innovation going on at Twilio with their Presto deployment, and we look forward to seeing what more they do! Thanks to Twilio for sharing their use case with the Presto community!
Link to watch the full video: https://www.youtube.com/playlist?list=PLJVeO1NMmyqXvoKFad0_SJ9C9AlqtVaQ3