Customer-Facing Presto at Rippling - Andy Li, Rippling
Last month we hosted PrestoCon, a return to in-person events that showcased the community development of Presto. In this blog we’ll detail Rippling’s presentation on their Presto use case, including their architecture, key optimizations, and hard earned lessons. You can also check out their full presentation here.

Background
Rippling is a popular HR and payroll platform that implemented the open source Presto project to improve database query performance and support the company's rapid growth. In his session Rippling software engineer Andi Li covered the benefits of using Presto for Rippling and how it has helped the company to better serve their customers. Rippling uses Presto as one query layer to support a variety of use cases and connect to various data sources, including Apache Pinot. The adoption of Presto has provided scale, federation, decoupling, and the benefits of open source technology to Rippling. In addition, Presto's support for custom functionality has allowed Rippling to extend its capabilities and better serve its customers:
Summary of Andy’s talk
Rippling is a growing company that connects everything related to employee management, including HR and IT, and uses a data platform at its core to power the various functions of the platform.
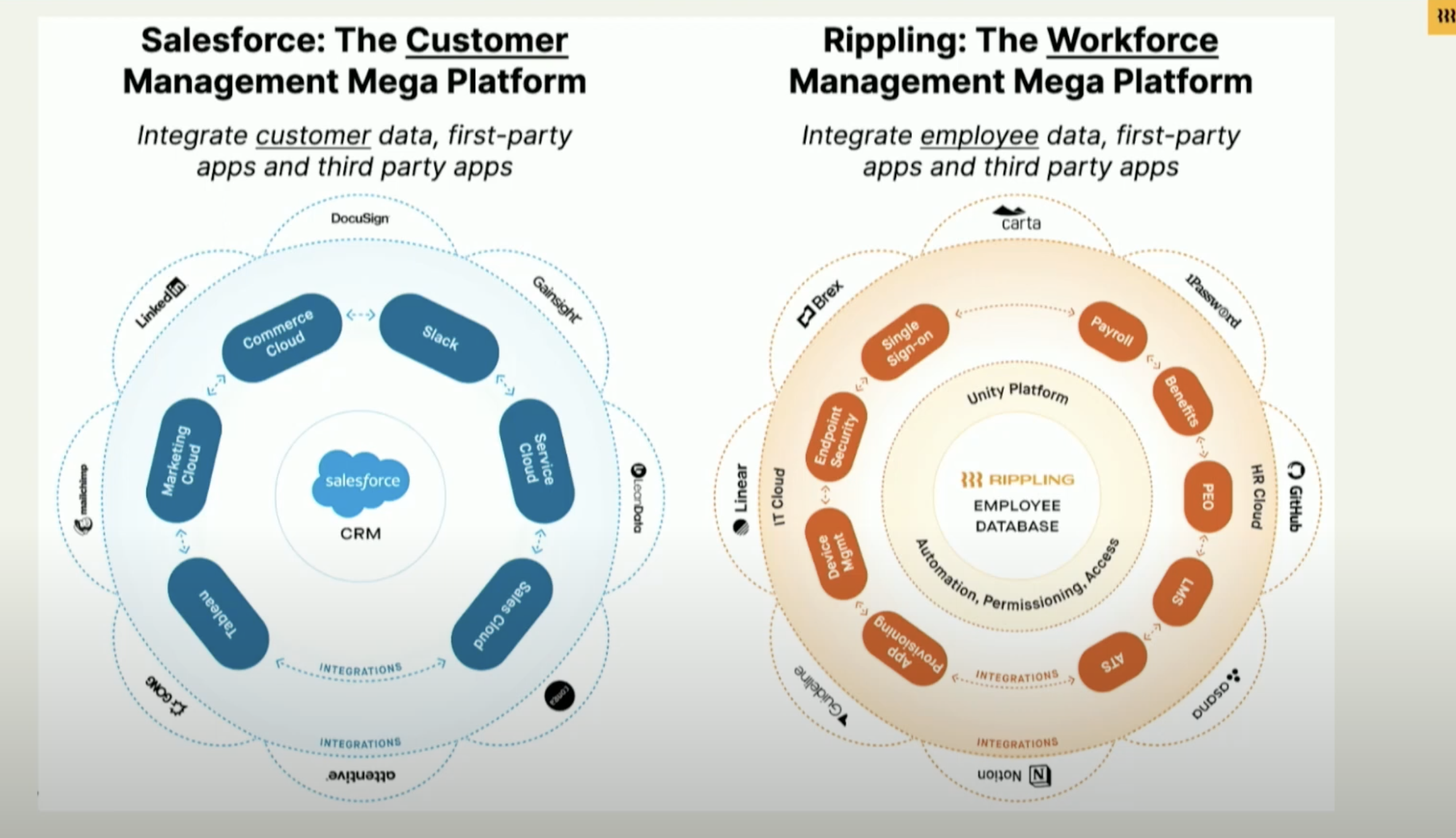
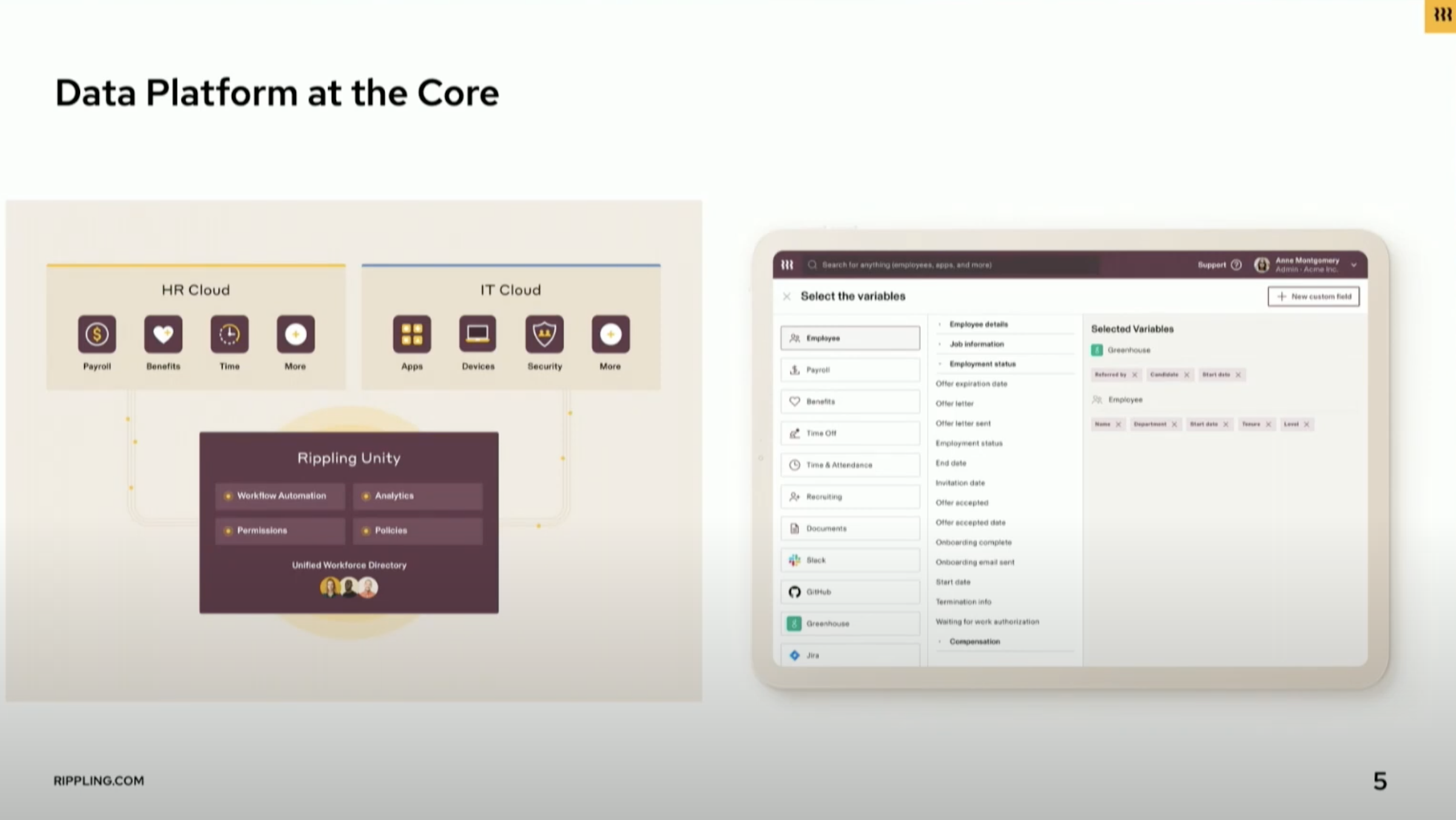
Rippling's customers can use RQL (Rippling Query Language, a SQL-like language developed at Rippling) to write custom functionality and drive workflows and automations.
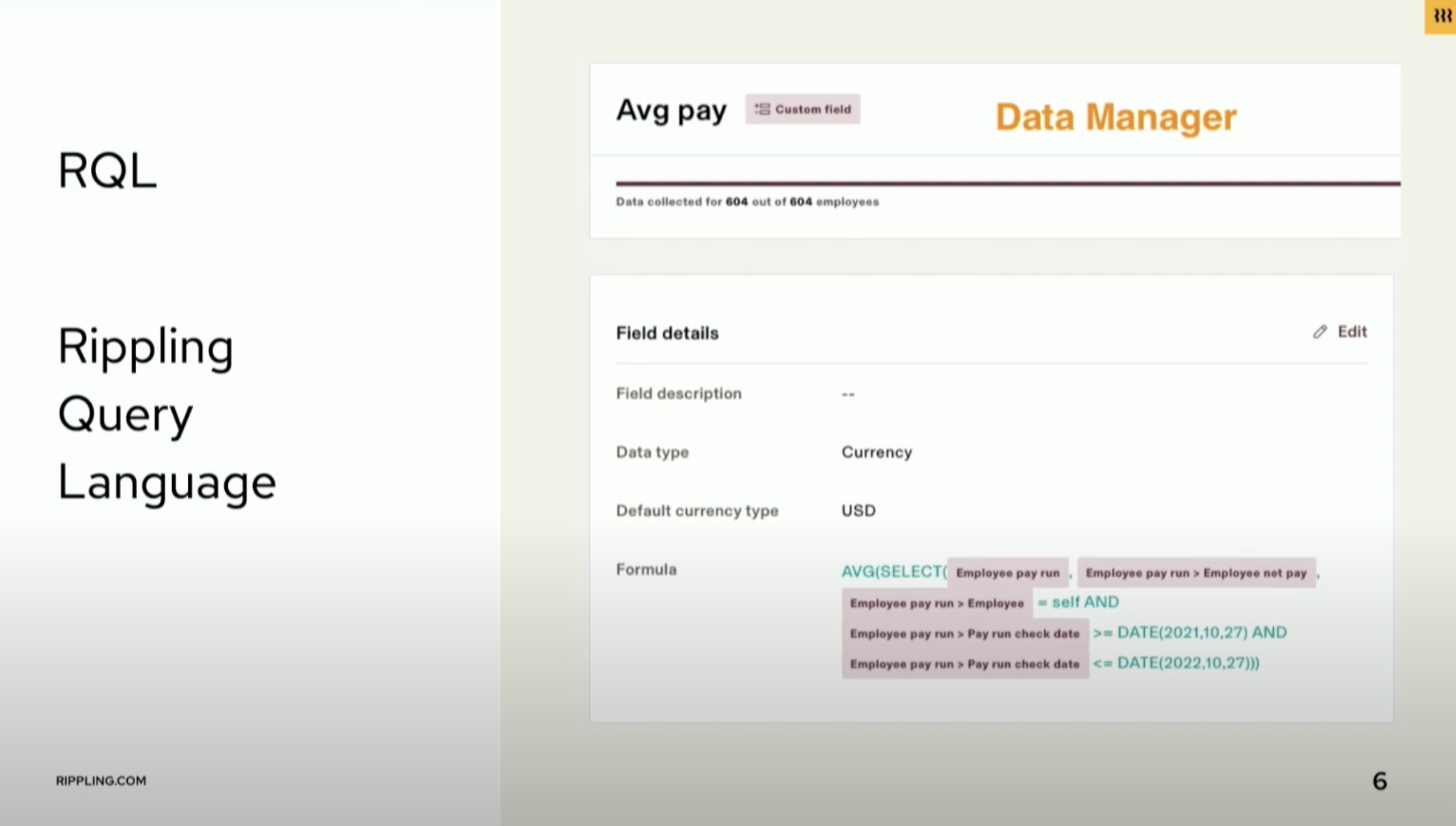

However, as the company experienced rapid growth, the number of RQL queries increased and put strain on the database.

To address this issue, Rippling turned to Presto to power their data platform and enable real-time querying at scale.

Rippling’s data architecture & benefits of Presto
One key aspect of their implementation of Presto is the use of Apache Pinot, a real-time OLAP system, for their product databases. While it allows for fast querying, there are still many use cases that do not fit into this system. That's where Presto comes in, enabling Rippling to connect to a variety of databases in order to support these additional use cases. One of the benefits of using Presto is the ability to scale horizontally. Both Presto and Pinot are built to handle large amounts of data and have been tested at companies with significant scale. Additionally, Presto enables federation for use as a single query layer to power their platform and connect to multiple data sources. As Rippling continues to grow, they are focusing on decoupling other components to run more efficiently. This involves moving from a monolithic structure to a microservices approach. Open source technology like Presto has been essential in this process, providing numerous benefits and opportunities for collaboration within the community. In terms of the overall architecture, Upstream data sources are fed into Pinot through Kafka, and then queried using Presto. Presto can access Pinot as well as other data sources in order to construct the desired query results.
One layer deeper
One area where they have particularly focused on utilizing Presto is in projection push down. This is important because they often have customers who write complex SQL queries that get translated into even more complex SQL statements. By pushing down certain operations, such as coalesces on multiple columns, they can save time and utilize the strengths of both Presto and Pinot. For example, pushing down string functions allows them to take advantage of Pinot's indexing and filtering capabilities, rather than relying on Presto to do the heavy lifting.
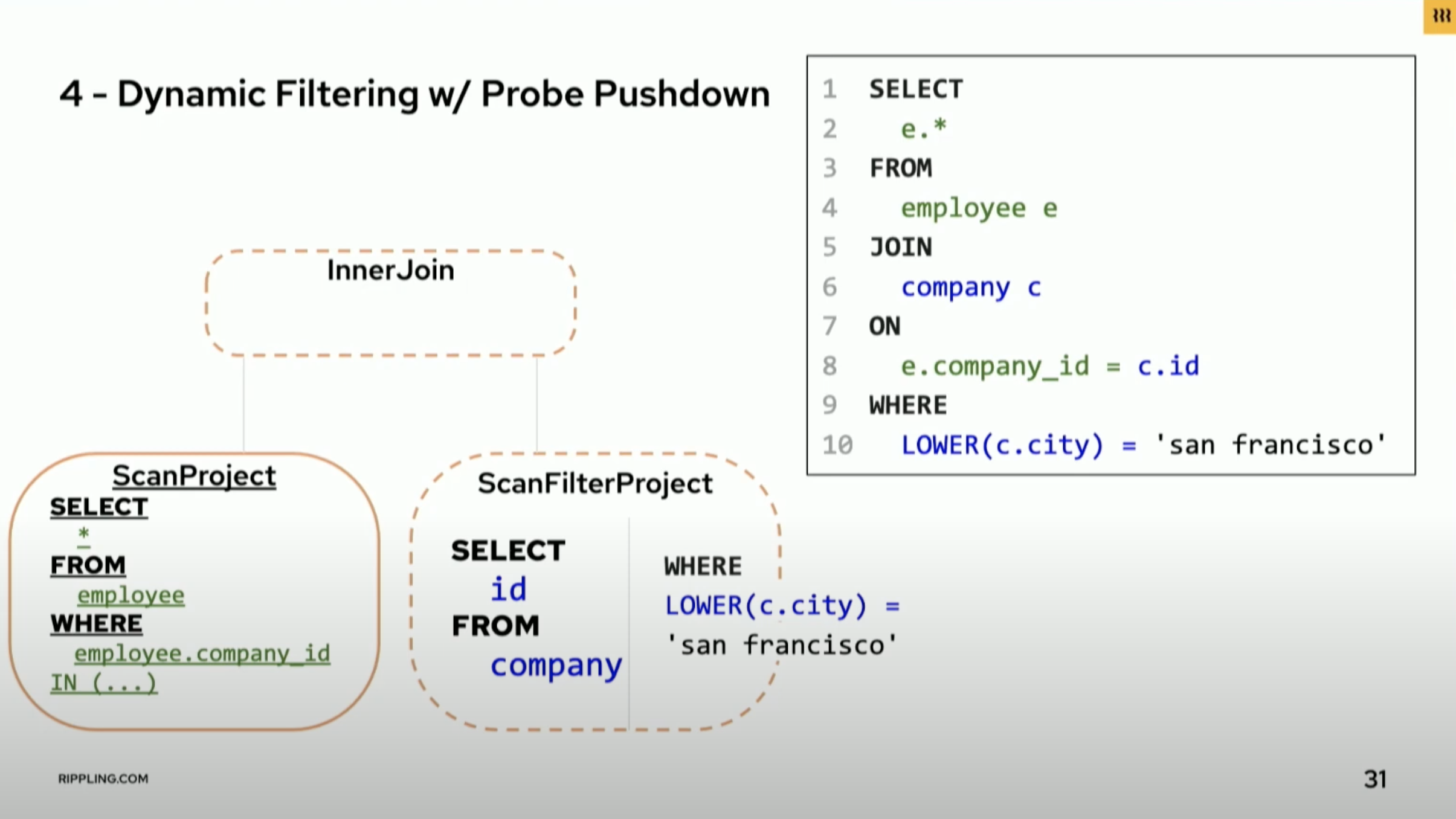
Another bottleneck they identified was in the area of dynamic filtering push down. In Presto, dynamic filtering allows for the filtering of data before the join stage, reducing the amount of data that needs to be joined. However, this can still involve a full table scan on one of the tables being joined. To address this issue, they implemented dynamic filtering push down, which pushes the filtering down into the connector and allows for the scan to be filtered as well. This results in a significant reduction in the amount of data being scanned and processed. Rippling has contributed much of their work back to the open source project as well, including these push down optimizations in addition to working on the Pinot-Presto connector and distributed tracing.
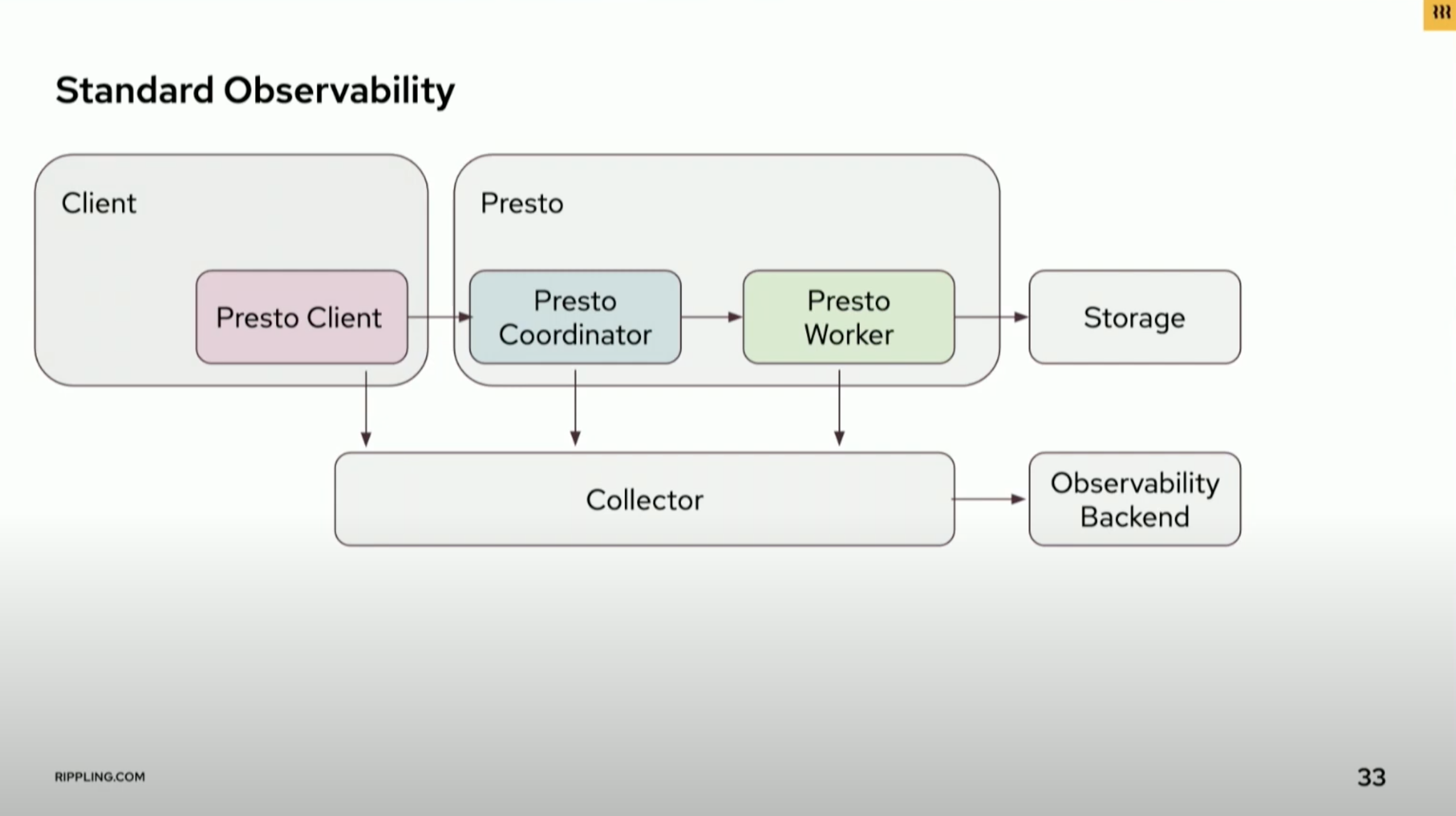
Overall, the use of Presto and Pinot allows Rippling to scale efficiently and support a wide range of use cases.

From the Presto Foundation
We’re excited to highlight Rippling at PrestoCon 2022. Thanks to Rippling for sharing their use case with the community!
Click here to watch the complete session.