Hudi tables via Presto-Hive connector: A Deep Dive
With the growing popularity of the lakehouse approach, it has become increasingly important for query engines to support these new formats such as Hudi. A previous blog discusses the evolution of presto-hudi integration via hive connector at a high level. With the latest community developments, a separate presto-hudi connector has come up but it is not at par with the hive connector in terms of security features, caching and cost-based optimization. Hive connector has CachingDirectoryLister which can be used for caching the splits for a given table for a configurable period of time. It also supports analyze command which helps in better planning during optimization phase. In this blog, we dive deeper into presto-hudi integration supported via hive connector from a developer's perspective and list down the various checkpoints where the query execution moves from presto to hudi library.
Input formats and Record readers
Before actually diving into the presto-hudi integration, let us first review a few related concepts. In the Hadoop world, data is stored in a logical file. This file can have various physical layouts (format) on remote storage. A "Path" identifies a file. Further, an "input format" abstraction allows reading portions (splits) of a file. To keep it short and sweet, input formats help generate splits from files which are logical representations of the data. Input formats provide record readers which do the actual reading from these splits.
InputFormat interface exposes 2 methods - getSplits() and getRecordReader().
Creation of splits
getSplits() method facilitates the creation of splits from actual data files. On a high level, this involves reading the input paths from the configuration object and scanning those paths to get the files present. Files are logically represented as FileStatus. These file paths are then passed to the makeSplit() method which creates the splits for further processing. Below are the snippets of the actual code where these calls are being made.
 Figure 1: listStatus() gets called internally from getSplits().
Figure 1: listStatus() gets called internally from getSplits().
 Figure 2: makeSplit() call is highlighted as part of getSplits() implementation.
Figure 2: makeSplit() call is highlighted as part of getSplits() implementation.
The above snippets are taken from FileInputFormat class. Please note that the lines are highlighted where these calls are being made.
Hudi table types
Hudi supports two types of tables, namely, Copy on Write (CoW) and Merge on Read (MoR). CoW is the simpler of the two in terms of the reading complexities involved. Upserts made to this table type result in newer versions of columnar parquet files which can be read efficiently using the native ParquetPageSource used internally by Presto.
MoR involves writing incoming updates to delta log files in avro format by default. These log files are later compacted to create new base parquet files. Since this involves row and columnar format files, this table type supports Read Optimized (RO) and Real Time (RT) queries. RO queries only scan parquet files, while RT queries merge parquet and log files on the fly to generate the latest snapshot.
To be able to query these tables, the table metadata needs to be synced with Hive or Glue metastore. Syncing MoR tables with the configured metastore results in the creation of 2 table types, <table_name>_ro and <table_name>_rt. They are internally differentiated by setting the config hoodie.query.as.ro.table. As the name suggests, the former is used for read optimized queries involving only base parquet files, while the latter is used for real time queries involving the merging of delta log files and base parquet files on the fly.
From Presto’s point of view, CoW table and _ro version of a MoR table behave the same way. However _rt version of MoR table type requires additional work as described in the next section.
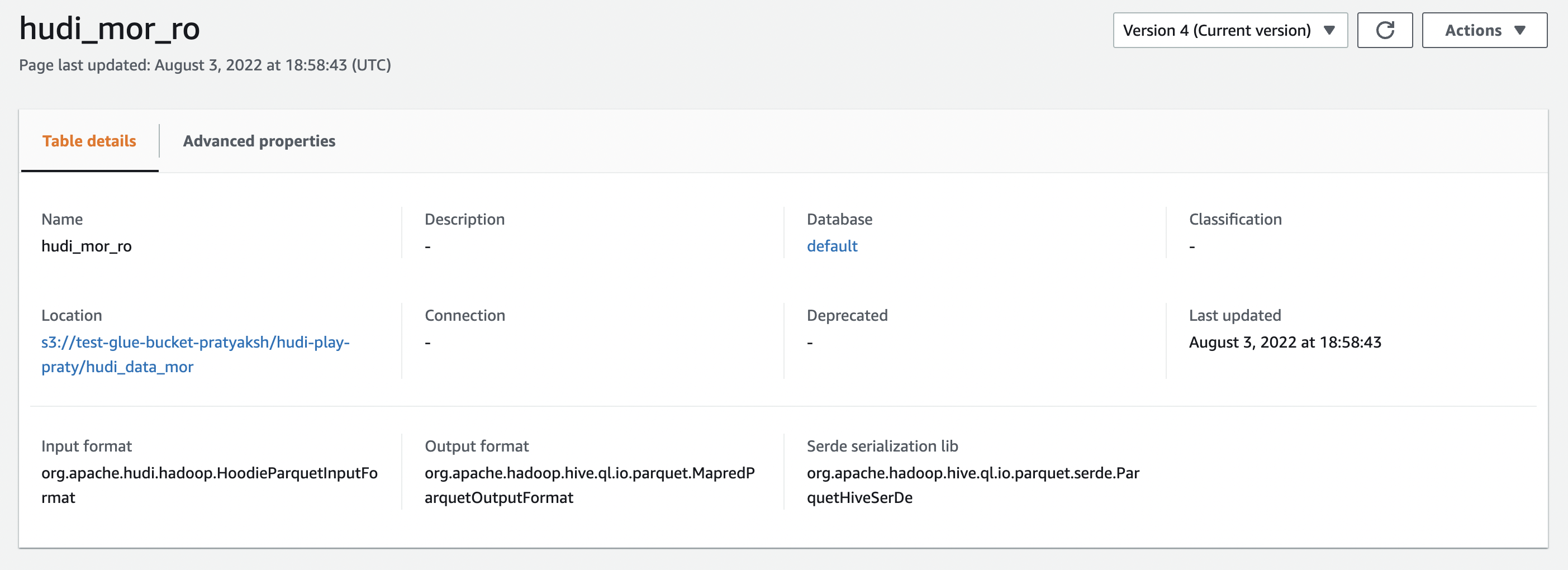
 Figure 3: Snapshot showing details about _ro table.
Figure 3: Snapshot showing details about _ro table.

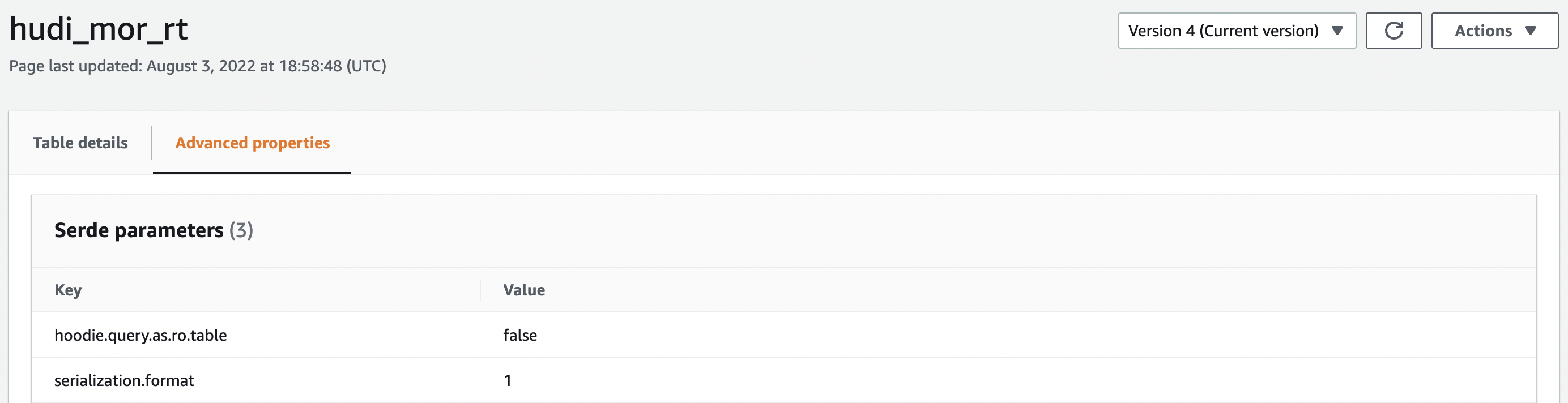 Figure 4: Snapshot showing details about _rt table.
Figure 4: Snapshot showing details about _rt table.
The above figures show the difference between the 2 versions of MoR tables in terms of table properties and input formats involved.
As is clearly visible, Hudi syncs the CoW and _ro tables with HoodieParquetInputFormat while _rt tables are registered with HoodieParquetRealtimeInputFormat.
Merge on Read table type
Currently presto supports read optimized and real time queries for MoR tables. After the parser, planner and optimizer phases, splits are generated by Presto which are used for creating presto pages to be rendered back to the client. We focus on this split generation phase and the record reader involved thereafter in the next sections.
Real time Queries
Below custom components are of interest to us for executing real time queries -
- HoodieParquetRealtimeInputFormat
- HoodieRealtimeFileSplit
- RealtimeFileStatus
- HoodieRealtimePath
- RealtimeCompactedRecordReader
- HoodieMergedLogRecordScanner
All the above classes are provided via hudi-hadoop-mr module in hudi repo, and we will see in some time how these classes are triggered.
BackgroundHiveSplitLoader performs the task of loading splits and it in turn delegates the task to StoragePartitionLoader.java class. StoragePartitionLoader loads the partitions. After verifying the annotations and inputFormat class here, inputFormat.getSplits() is called. This is the first place where Hudi’s custom logic is called. Before diving deeper, let us have a look at the class hierarchies below -
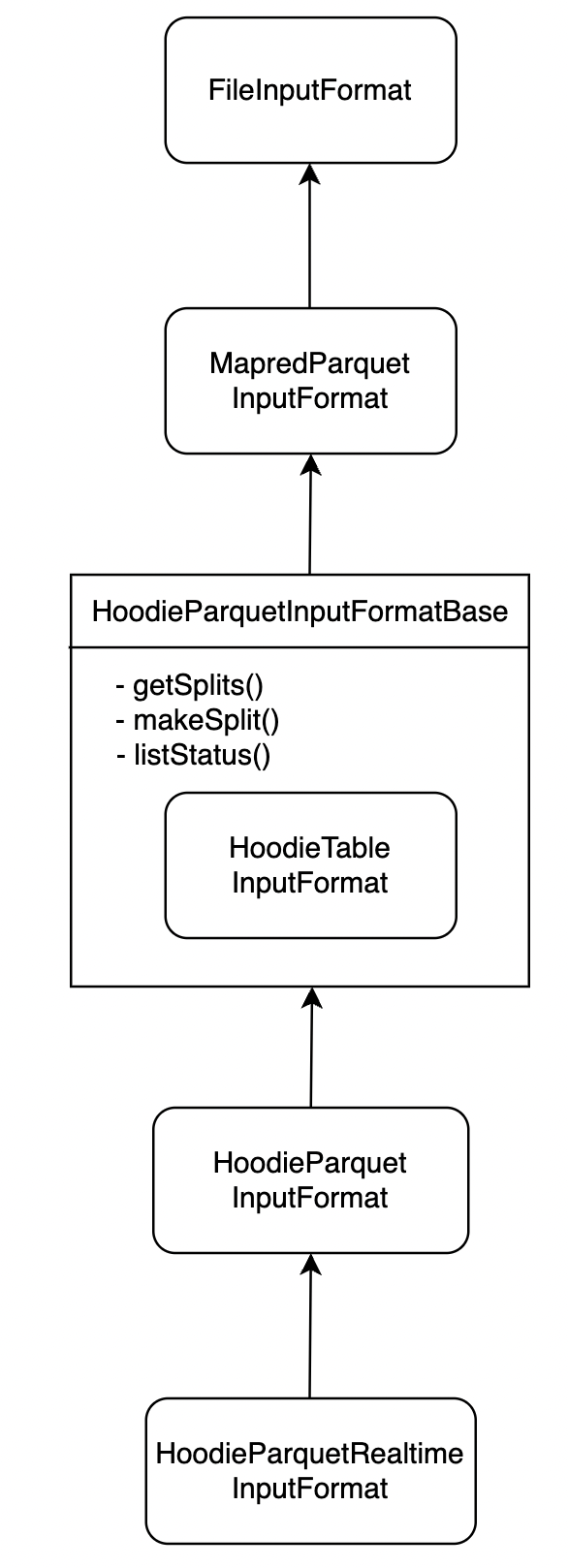
Figure 5: Input format hierarchy.
HoodieTableInputFormat is an abstract class and is implemented as below -
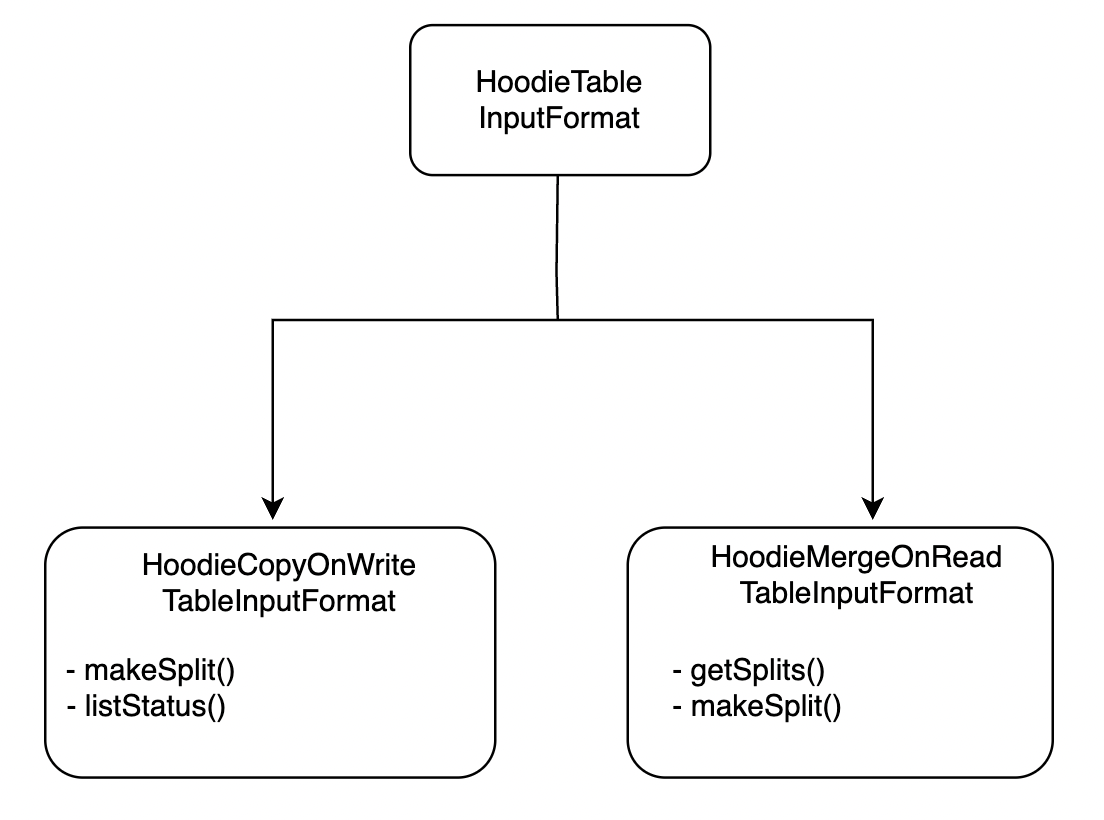 Figure 6: HoodieTableInputFormat implementations.
Figure 6: HoodieTableInputFormat implementations.
For _rt tables, input format is registered as HoodieParquetRealtimeInputFormat. Hence when inputFormat.getSplits() is called, it calls HoodieParquetInputFormatBase.getSplits() which delegates the call to HoodieTableInputFormat which is implemented as HoodieMergeOnReadTableInputFormat.getSplits(). This makes a call to FileInputFormat.getSplits().
Now refer to Figure 1, listStatus() is called which is overridden in HoodieCopyOnWriteTableInputFormat.listStatus(). This method in turn calls listStatusForIncrementalMode() and listStatusForSnapshotMode(). This will return RealtimeFileStatus. RealtimeFileStatus overrides getPath() method which returns HoodieRealtimePath. Please refer to the below figures -
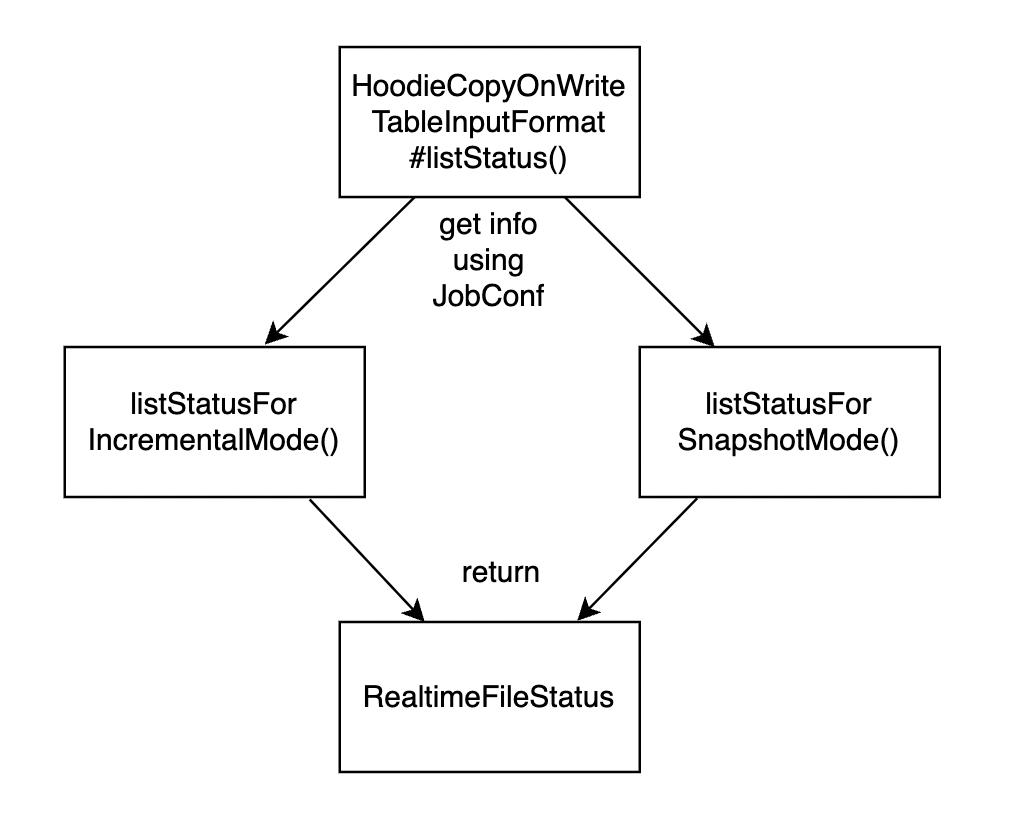 Figure 7: listStatus() call for MoR table type returns RealtimeFileStatus.
Figure 7: listStatus() call for MoR table type returns RealtimeFileStatus.

Figure 8: makeSplit() internally called from getSplits() for MoR table type returns HoodieRealtimeFileSplit.
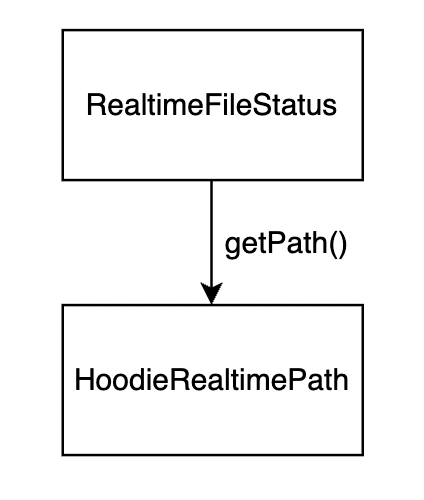
Figure 9: getPath() is overridden in RealtimeFileStatus and it returns HoodieRealtimePath.
Now that real time splits got generated, we need a way of reading the records from these special splits. These splits contain information about the base parquet files as well as delta avro files for the queried snapshot. To be able to generate the snapshot, records from both types of files need to merged on the fly. Native ParquetPageSource we talked about earlier can only scan parquet files, hence we need a custom record reader which is provided by Hudi. GenericHiveRecordCursorProvider calls createRecordReader which ultimately calls inputFormat.getRecordReader(). This returns RealtimeCompactedRecordReader by default. Please refer to the below figure -
 Figure 10: Real time record reader.
Figure 10: Real time record reader.
Read Optimized Queries
These queries will occur from <table_name>_ro table registered in HMS and it has HoodieParquetInputFormat as the input format. These queries will only read the base parquet files, hence the name read optimized. The execution of these queries is exactly similar to that for CoW table type. Please refer to the next section for more details.
Copy on Write table type
The layout of this table type only consists of parquet files. This makes use of the HudiDirectoryLister class for listing relevant data files. HudiDirectoryLister is a singleton object and gets created once every query involving hudi CoW table. This class creates the hudi timeline by scanning the .hoodie folder, then creates a file system view on top of this timeline. FileSystemView is a logical representation of the hudi storage layout which binds the timeline and data files together.
Unlike HadoopDirectoryLister, this lister does not make use of the file listing cache since the hudi table is assumed to be ever-evolving and hence the partitions are not sealed. Once the splits are created, native ParquetPageSource is used for rendering the results.
We hope this blog was useful in understanding the code level interaction between presto and hudi. Contributions are welcome to improve this blog and write new ones. Should you have any doubts, please join the Presto slack channel or engage via github issues.