Presto's architecture originally only supported a single coordinator and a pool of workers. This has worked well for many years but created some challenges.
With a single coordinator, the cluster can scale up to a certain number of workers reliably. A large worker pool running complex, multi-stage queries can overwhelm an inadequately provisioned coordinator, requiring upgraded hardware to support the increase in worker load.
A single coordinator is a single point of failure for the Presto cluster.
To overcome these challenges, we came up with a new design with a disaggregated coordinator that allows the coordinator to be horizontally scaled out across a single pool of workers.
Co-authors Denny Lee, Sr. Staff Developer Advocate at Databricks
This is a joint publication by the PrestoDB and Delta Lake communities
Due to the popularity of both the PrestoDB and Delta Lake projects (more on this below), in early 2020 the Delta Lake community announced that one could query Delta tables from PrestoDB. While popular, this method entailed the use of a manifest file where a Delta table is registered in Hive metastore as symlink table type. While this approach may satisfy batch processing requirements, it did not satisfy frequent processing or streaming requirements. Therefore, we are happy to announce the release of the native Delta Lake connector for PrestoDB (source code | docs).
Raptor is a Presto connector (presto-raptor) that is used to power some critical
interactive query workloads in Meta (previously Facebook). Though referred to in the ICDE 2019 paper
Presto: SQL on Everything, it remains somewhat mysterious to many
Presto users because there is no available documentation for this feature. This article will shed some light on the history of Raptor, and why
Meta eventually replaced it in favor of a new architecture based on local caching, namely RaptorX.
The story of Raptor
Generally speaking, Presto as a query engine does not own storage. Instead, connectors were developed to query different external data sources.
This framework is very flexible, but in disaggregated compute and storage architectures it is hard to offer low latency guarantees. Network and
storage latency add difficult to avoid variability. To address this limitation, Raptor was designed as a shared-nothing storage engine for Presto.
Motivation – an initial use case in the AB testing framework
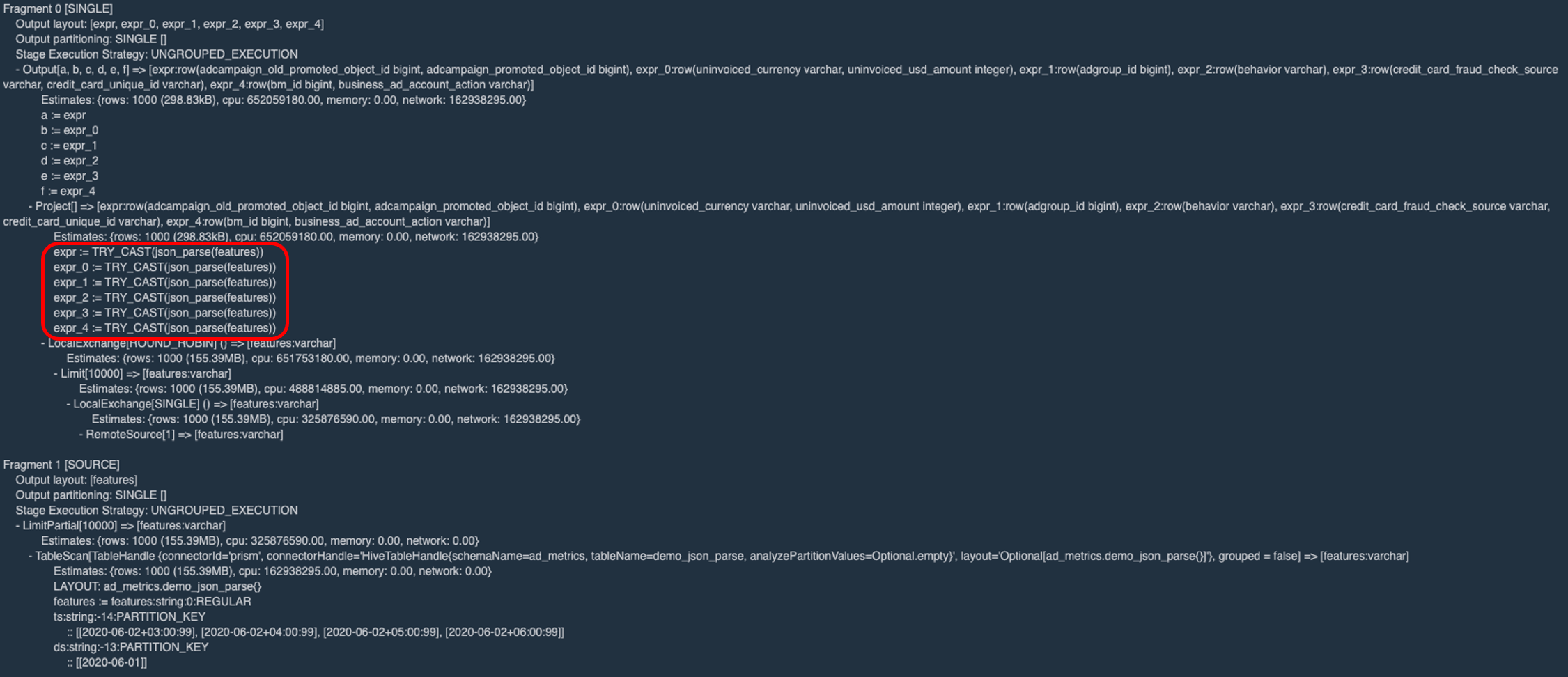
One common pattern we see in some analytical workloads is the repeated use of the same, often times expensive expression. Look at the following query plan for example:
The expression JSON_PARSE(features) is used 6 times, and casted to different ROW structures for further processing. Traditionally, Presto would just execute the expression 6 times, in 6 separate projections. Since Presto would generate efficient bytecode for each projection, this would not be a problem as long as the expression itself is not expensive. For example, executing x+y 6 times in a cache efficient way would not necessarily incur a big performance overhead. However, running expensive string manipulations like JSON_PARSE or REGEX operations multiple times could quickly add up.
Presto was originally designed to run interactive queries against data warehouses, but now it has evolved into a unified SQL engine on top of open data lake analytics for both interactive and batch workloads. Popular workloads on data lakes include:
1. Reporting and dashboarding
This includes serving custom reporting for both internal and external developers for business insights and also many organizations using Presto for interactive A/B testing analytics. A defining characteristic of this use case is a requirement for low latency. It requires tens to hundreds of milliseconds at very high QPS, and not surprisingly this use case is almost exclusively using Presto and that's what Presto is designed for.
2. Data science with SQL notebooks
This use case is one of ad hoc analysis and typically needs moderate latency ranging from seconds to minutes. These are the queries of data scientist, and business analysts who want to perform compact ad hoc analysis to understand product usage, for example, user trends and how to improve the product. The QPS is relatively lower because users have to manually initiate these queries.
3. Batch processing for large data pipelines
These are scheduled jobs that are running every day, hour, or whenever the data is ready. They often contain queries over very large volumes of data and the latency can be up to tens of hours and processing can range from CPU days to years and terabytes to petabytes of data.
Presto works exceptionally effectively for ad-hoc or interactive queries today, and even some batch queries, with the constraint that the entire query must fit in memory and run quickly enough that fault tolerance is not required. Most ETL batch workloads that don’t fit in this box are running on “very big data” compute engines like Apache Spark. Having multiple compute engines with different SQL dialects and APIs makes managing and scaling these workloads complicated for data platform teams. Hence, Facebook decided to simplify and build Presto on Spark as the path to further scale Presto. Before we get into Presto on Spark, let me explain a bit more about the architecture of each of these two popular engines.
With the wide deployment of Presto in a growing number of companies, Presto is used not only for queries, but also for data ingestion and ETL jobs. There is a need to improve Presto’s file writer performance, especially for popular columnar file formats, e.g. Parquet, and ORC. In this article, we introduce the brand new native Parquet writer for Presto, which writes directly from Presto's columnar data structure to Parquet's columnar values, with up to 6X throughput improvement and less CPU and memory overhead.
Girish Baliga, Chair, Presto Foundation, Presto Foundation Member: Uber
Tim Meehan, Chair, Presto Foundation, Technical Steering Committee, Presto Foundation Member: Facebook
Dipti Borkar, Chair, Presto Foundation, Outreach, Presto Foundation Member: Ahana
Amit Chopra, Board member, Presto Foundation Member: Facebook
Zhenxiao Luo , Board member, Presto Foundation Member: Twitter
Arijit Bandyopadhyay, Board member, Presto Foundation Member: Intel
Steven Mih, Board member, Presto Foundation Member: Ahana
Bin Fan, Outreach team member, Presto Foundation Member: Alluxio
We recently wrapped up an amazing PrestoCon Day attended by over 600 people from across the globe. The technical discussions and the panel was a clear indication of the growing community. We showcased a number of features contributed by various companies that continue to advance the mission of Presto open source, reiterating our commitment to grow the Presto community and support the continued improvement of the core technology.
Facebook: Abhinav Sharma, Amit Dutta, Baldeep Hira, Biswapesh Chattopadhyay, James Sun, Jialiang Tan, Ke Wang, Lin Liu, Naveen Cherukuri, Nikhil Collooru, Peter Na, Prashant Nema, Rohit Jain, Saksham Sachdev, Sergey Pershin, Shixuan Fan, Varun Gajjala
Alluxio: Bin Fan, Calvin Jia, Haoyuan Li
Twitter: Zhenxiao Luo
Pinterest: Lu Niu
RaptorX is an internal project name aiming to boost query latency significantly beyond what vanilla Presto is capable of. This blog post introduces the hierarchical cache work, which is the key building block for RaptorX. With the support of the cache, we are able to boost query performance by 10X. This new architecture can beat performance oriented connectors like Raptor with the added benefit of continuing to work with disaggregated storage.
Tl;dr: 2020 was a huge year for the Presto community. We held our first major conference, PrestoCon, the biggest Presto event ever. We had a massive expansion of our meetup groups with more than 20 sessions held throughout the year, and significant innovations were contributed to Presto!
This year has certainly been unique, to say the least. As chairperson of the Presto Foundation Outreach Committee, the term “outreach” took on a whole new meaning this year. But through the challenges of 2020, we adopted new ways to connect. We continued to build and engage with the Presto community in a new “virtual” way, and I couldn’t be more proud of all we’ve accomplished as a community in 2020.
Function evaluation is a big part of projection CPU cost. Recently we optimized a set of functions that use TypedSet, e.g. map_concat, array_union, array_intersect, and array_except. By introducing a new OptimizedTypeSet, the above functions saw improvements in several dimensions:
Up to 80% reduction in wall time and CPU time in JMH benchmarks
Reserved memory reduced by 5%
Allocation rate reduced by 80%
Furthermore, OptimizedTypeSet resolves the long standing issue of throwing EXCEEDED_FUNCTION_MEMORY_LIMIT for large incoming blocks: "The input to function_name is too large. More than 4MB of memory is needed to hold the intermediate hash set.”
The OptimizedTypeSet and improvements to the above mentioned functions are merged to master, and will be available from Presto 0.244.